Data Quality Management: Boost Data Accuracy & Insights
Explore our comprehensive guide on data quality management to improve accuracy, drive growth, and make smarter, informed decisions.
By Matthew Clarkson · July 25, 2025

Data quality management isn’t a project you complete once and tick off a list. It’s a continuous, disciplined process of making sure your organisation’s data is accurate, complete, and consistent. Think of it as the ongoing work required to transform messy, unreliable information into a genuinely valuable strategic asset.
Why Data Quality Management Is Your Competitive Edge
Trying to run a business on bad data is like navigating with a faulty maps. Imagine the streets are mislabelled, key locations are missing, and entire suburbs are just plain wrong. You’d waste time, burn through fuel, and probably never reach your destination. This is precisely what happens when your data is a mess—it leads directly to flawed strategies and expensive mistakes.
This is why data quality management (DQM) is much more than a technical task for the IT department – it’s a foundational business strategy.
Let’s use an analogy. A master chef wouldn’t dream of starting a signature service without first sourcing the absolute best ingredients. They need the freshest produce, the finest cuts, the most fragrant spices. Without that high-quality foundation, their culinary masterpiece would fall flat, no matter how skilled they are.
Your business operates on the same principle. Clean, reliable, and timely data is the essential ingredient for everything you do—from your financial forecasting and marketing campaigns to your supply chain logistics and customer service.
The Real Cost of Bad Data
The fallout from poor data quality isn’t just a theoretical problem. It has very real, damaging effects on every corner of the business. When your data can’t be trusted, you inevitably:
- Launch misguided marketing campaigns: You end up targeting the wrong people with irrelevant offers simply because your customer profiles are patchy or out-of-date.
- Break your supply chain: Inaccurate inventory data leads to costly stockouts or, just as bad, overstocking, which ties up capital and disrupts operations.
- Erode customer trust: Little things like misspelling a customer’s name, sending mail to an old address, or failing to recognise a loyal client can do immense damage to your reputation.
- Generate flawed financial reports: Inaccurate sales or expense figures create a ripple effect, leading to poor financial planning and serious compliance risks.
These aren’t minor inefficiencies; they carry a massive financial burden. Statistical analyses show that data-related issues cost Australian businesses millions every year. This aligns with global research suggesting poor data quality can chew up 20-30% of a company’s revenue. For a large Australian enterprise, that can easily mean losses in the tens of millions annually, all stemming from data that’s inaccurate or poorly governed.
Ultimately, data quality management is about building a foundation of trust. It ensures that when you make a decision, you are acting on a clear and accurate picture of reality, not a distorted one. This reliability is what separates market leaders from the competition.
Putting solid DQM practices in place is like swapping that faulty paper map for a precise, real-time GPS. It gives you the clarity and confidence to navigate the complexities of the modern market, turning your data from a potential liability into your most powerful competitive advantage.
The Building Blocks of High-Quality Data

When we talk about data quality, it’s easy to get lost in technical jargon. But at its heart, effective data quality management comes down to a few core principles. These aren’t abstract concepts; they are the fundamental checks that tell you whether your data is a genuine asset or a hidden liability.
Think of it like inspecting a critical piece of machinery. You wouldn’t just give it a quick glance; you’d check every component against a strict set of criteria. Each one has to be up to scratch for the whole machine to run smoothly. The same logic applies to your data. Let’s break down the six essential dimensions of high-quality data and what they actually mean for your business.
Accuracy: The Reality Check
First up is accuracy. This dimension simply measures how well your data lines up with the real world. Is the information you have on file actually correct? An inaccurate dataset is like a GPS directing you down a road that was demolished last year—it’s not just wrong, it’s actively misleading.
For example, a customer’s address recorded as “123 Main St” when they really live at “132 Main St” might seem like a small typo. But that one mistake leads to failed deliveries, wasted shipping costs, and a seriously annoyed customer. It’s a direct hit to both your bottom line and your brand’s reputation.
Completeness: The Whole Story
Next is completeness. This one asks if you have all the pieces of the puzzle. It’s entirely possible for your data to be 100% accurate but still be useless if key information is missing. You can’t see the full picture if a third of the puzzle pieces are gone.
Imagine your marketing team is thrilled to launch a new SMS campaign, only to find that 40% of your customer records are missing a mobile number. Suddenly, the campaign’s reach is slashed, and a huge chunk of your investment and strategic planning goes down the drain. To get the full story, you often need to do more than just collect data; you might need to actively fill in the gaps. For a closer look, you can learn more about practical data cleansing techniques that directly improve completeness.
Consistency: The Single Source of Truth
Consistency is all about making sure your data tells the same story everywhere it appears. When data is inconsistent across different systems, you get chaos. It creates a mess that makes reliable reporting impossible. It’s like having two clocks in the same room showing different times—which one do you trust?
A classic business example is a retailer that records a sale in “NSW” in its point-of-sale system but as “New South Wales” in its inventory platform. When someone tries to run a report on state-wide performance, the systems treat them as two different places. The result is fragmented analytics and decisions based on flawed insights.
The goal of data quality management is not just to fix errors but to establish a trusted, unified view of your business reality. Each dimension works together to build this foundation of trust.
Timeliness: The Expiry Date
Data, like fresh produce, has an expiry date. Timeliness refers to how up-to-date and relevant your information is right now. Data that was perfectly accurate yesterday could be completely irrelevant today. Relying on stale data is like using last week’s weather forecast to plan a picnic; the situation has changed.
Think about a financial advisor using a client’s portfolio value from three weeks ago to make a critical investment decision. The market can shift dramatically in that time, rendering the old data useless and any action based on it incredibly risky.
Uniqueness: The No-Duplicates Rule
Uniqueness is the principle that ensures you have only one record for each single entity. Duplicates might seem harmless, but they bloat your databases, skew your analytics, and create frustrating customer experiences. It’s the digital equivalent of having the same person in your phone contacts three times under slightly different names.
If a customer named “Jonathan Smith” also exists as “Jon Smith” and “J. Smith” in your CRM, he might receive three identical promotional letters. This doesn’t just waste postage; it makes your organisation look unprofessional and disorganised.
Validity: The Rule Book
Finally, there’s validity. This dimension confirms that your data follows the rules you’ve set for it. Data needs to be in the right format and fall within a logical range to be usable. For instance, an email address field containing an entry without an “@” symbol is invalid. A customer’s date of birth set in the future is also obviously invalid. These are records that fail a basic logic test and can easily break automated processes.
Your Blueprint for a Data Quality Framework
Trying to manage data without a proper framework is a lot like going on a crash diet. You might see some quick, impressive results, but they rarely last. A one-off data clean-up project might make your reports look good for a month, but without a sustainable system, you’ll be right back where you started.
A formal data quality management framework, on the other hand, is the healthy lifestyle equivalent. It’s a structured, cyclical approach that helps you diagnose, fix, and continuously monitor the health of your data. It’s not about a single project with a start and finish line; it’s about embedding a perpetual cycle of improvement into your daily operations. This is how you turn data quality from an occasional chore into a core, value-driving business function.
Starting with Data Profiling
Every good plan starts with understanding the current situation. In the world of data, that means data profiling. Think of it as a comprehensive diagnostic check-up for your data assets. You can’t prescribe a cure without a proper diagnosis, and you certainly can’t fix data problems you don’t know exist.
Data profiling involves running analytical techniques over your datasets to get a crystal-clear summary of their condition. It’s all about uncovering the reality hiding in your systems.
- Discovering Patterns: It helps you understand the true structure and content of your data, often revealing patterns or connections you never knew were there.
- Identifying Issues: More importantly, it shines a bright light on quality problems like null values, incorrectly formatted fields, or duplicate records. This pinpoints exactly where your data hygiene is failing.
- Setting a Baseline: This initial analysis gives you a starting point—a set of concrete metrics you can use to measure the success of your data quality efforts down the track.
Defining Quality Rules and Cleansing Data
Once profiling has exposed the weak spots, it’s time to define your standards. This means creating clear, unambiguous data quality rules that are tied directly to your business needs. These rules become the official definition of what “good” data looks like for your organisation. For instance, a rule might state that every customer record must have a valid, properly formatted postcode.
With those rules in place, you can move on to the hands-on work: data cleansing and enrichment. This is the active repair phase where you correct all the errors you found during profiling. It could involve fixing typos, merging duplicate entries, standardising formats (like changing all instances of “NSW” to “New South Wales”), and even enriching incomplete records with trusted information from third-party sources.
This flow chart gives you a sense of how these initial steps work together to build the foundation of a solid framework.
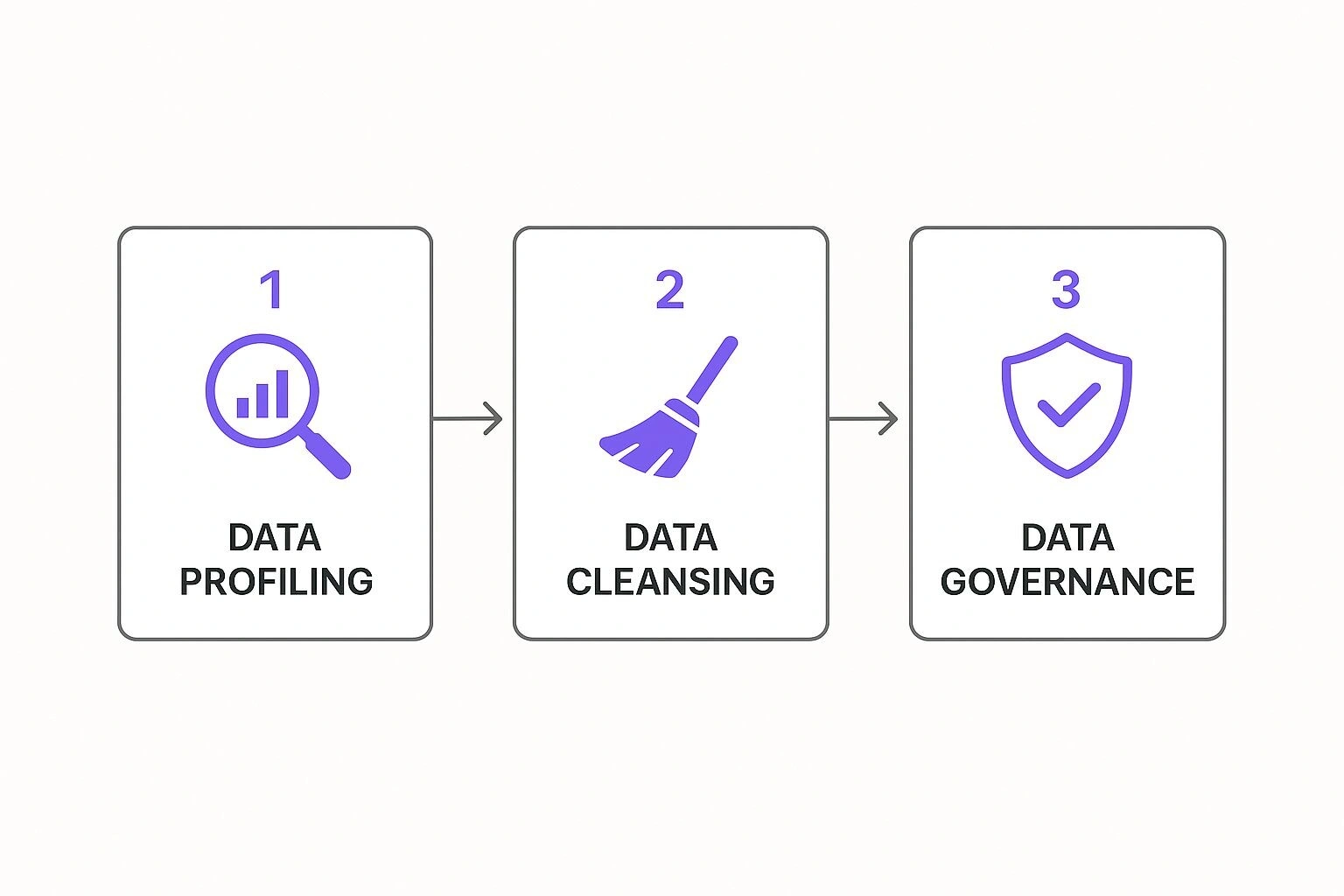
As you can see, it’s a logical progression from diagnosing issues via profiling to actively fixing them through cleansing, all held together by strong governance.
Monitoring and Governance for Long-Term Health
The final, and arguably most critical, piece of the puzzle is continuous monitoring and governance. A one-time cleanse is almost guaranteed to fail if you don’t have a plan to stop new bad data from getting in. This is where automation and clear ownership become non-negotiable.
A data quality framework is not a project; it’s a program. Its goal is to create an organisational immune system that automatically detects and neutralises data threats before they can spread and cause harm.
Automated monitoring tools can keep an eye on your data quality metrics in real time, flagging issues the moment they appear. This proactive approach lets you stamp out problems immediately, long before they have a chance to corrupt your analytics and throw your business processes into chaos.
This commitment to high-quality data isn’t just an internal best practice anymore; it’s increasingly recognised at a national level. The Australian Data Strategy, for example, points to data quality management as a core pillar for building a mature, data-driven economy. The goal is for businesses and government alike to rely on high-quality information to innovate and create better policies. You can read more about the national strategy and its goals to see how this thinking aligns with broader economic and technological trends.
Embedding Data Quality Into Your Company Culture

You can have the most advanced data quality tools on the market, but they’ll ultimately fall flat if your company’s culture doesn’t back them up. Technology is just an enabler. The real, lasting success in data quality management comes from weaving data integrity into the very DNA of your organisation. It’s about shifting the mindset from data quality being an “IT problem” to it being a shared responsibility that everyone owns.
This kind of sustainable DQM is really about empowering your people and refining your processes, not just installing the latest software. It means fostering an environment where every single employee understands how their actions directly affect the accuracy and reliability of the company’s data. Once that cultural shift happens, data quality stops being a frantic, reactive clean-up job and becomes a proactive, business-as-usual habit.
Establishing Clear Data Ownership
The very first step in building this culture is to eliminate ambiguity. You need clear lines of data ownership and data stewardship. These aren’t just fancy job titles; they are crucial roles that assign direct accountability for your most important data assets.
- Data Owners: These are typically senior business leaders. Think of the Head of Sales “owning” customer data. They are strategically accountable for the quality of their data domain and have the final say on its rules and definitions.
- Data Stewards: These are the subject matter experts who are hands-on with the data every day. For instance, a CRM manager might be the steward for that customer data. Their job is the tactical management—monitoring, fixing, and maintaining data quality to meet the standards the owner has set.
By assigning these roles, you make sure someone is always on the hook. There’s no more finger-pointing or confusion about who needs to fix an error. The ownership structure provides immediate clarity and, more importantly, drives action.
Weaving Quality into Daily Workflows
A truly data-aware culture doesn’t treat quality checks like some separate, annoying task. Instead, it builds them directly into the daily workflows where data is born and used. Think of it like building quality control right onto the factory assembly line, rather than waiting to inspect the final product for defects.
In practice, this means putting validation rules at the point of data entry in your CRM or running automated checks every time a new dataset lands in your warehouse. When you catch errors at the source, you stop them from spreading and corrupting your downstream analytics and operations. This proactive approach is infinitely more efficient than conducting massive, painful clean-ups every few months.
Lasting data quality is the result of a thousand small, correct actions performed every day. It’s a culture of diligence, not a series of heroic clean-up projects.
This principle of transparent data quality reporting is gaining serious ground, even at the government level. In Australia, for example, the NSW Government’s Data Quality Reporting Tool is a brilliant initiative. It helps people who look after datasets create clear “Data Quality Statements”. The result? Datasets with these statements are downloaded nearly twice as often, proving that users actively seek out information they know they can trust.
The screenshot above shows just how intuitive the NSW tool is. It uses a simple questionnaire to guide users through assessing data attributes like accuracy and completeness. This structured approach empowers non-technical users to describe the state of their data, fostering a shared understanding of its fitness for any given purpose.
Case Study: A Retailer’s Cultural Transformation
Let’s look at a real-world example. A large retail company was constantly battling stockouts and running marketing promotions that just weren’t hitting the mark. It turned out their inventory data was a complete mess, and their customer database was riddled with duplicates and old information. They quickly realised that throwing more technology at the issue wasn’t fixing the core problem: a fundamental lack of ownership.
So, they kicked off a culture change program. The Head of Merchandising was made the official “owner” of all product data. Store managers became “stewards,” responsible for the inventory accuracy in their individual locations. Over in marketing, the CMO took ownership of customer data, with the CRM specialists acting as its stewards.
They then integrated simple data quality dashboards into the tools these teams used every single day. Store managers could see their inventory accuracy scores in real-time. Marketers were alerted to duplicate customer records the moment they were entered. This simple shift made data quality tangible and personal. The results were astounding. Within a year, their inventory accuracy shot up by over 95% , and their targeted marketing campaigns—now built on a foundation of clean data—drove record sales during the crucial holiday season.
How to Choose the Right Data Quality Tools
https://www.youtube.com/embed/sxHGNhCXZHU
Choosing the right data quality tool feels a lot like buying a vehicle. You wouldn’t buy a Ferrari to haul timber, and a semi-trailer is a bit much for the daily school run. There’s no single “best” tool on the market—only the tool that’s the best fit for your specific business, your existing infrastructure, and the scale you operate at.
The software market for data quality management is crowded and, frankly, a bit confusing. To really cut through the noise, you need a clear way to evaluate your options that focuses on what a tool actually does, not just its brand name. This approach helps you make an investment that solves your genuine problems instead of just buying the shiniest new toy.
Start With Core Functional Needs
Before you even think about looking at vendors, you need to play doctor and diagnose your own data quality pains. Are your biggest headaches coming from inaccurate customer addresses? Maybe it’s inconsistent product codes causing chaos across different systems, or a constant flood of duplicate leads clogging up your sales pipeline.
Pinpointing where it hurts the most allows you to prioritise what you need a tool to do. A solid evaluation always starts by mapping your problems to a tool’s core functions:
- Data Profiling: This is the diagnostic phase. These features scan your datasets to give you a clear picture of their structure, content, and overall health. It’s the essential first step to understanding what’s really going on under the hood.
- Data Cleansing and Standardisation: Think of this as the hands-on repair work. These tools are built to correct errors, standardise formats (like turning “NSW” into “New South Wales”), and break down complex data into clean, usable components.
- Data Matching and Deduplication: If you’re trying to build a single source of truth, this is non-negotiable. These functions are designed to find and merge duplicate records for things like customers or products, creating one clean, consolidated view.
- Data Monitoring: This is your early warning system. Proactive monitoring tools keep an eye on your data quality in real-time and send alerts when new issues pop up, helping you stop bad data at the source before it can spread.
Once you have this clear picture of your priorities, you can start assessing potential software solutions far more effectively. Strong validation capabilities are also a must-have; you can explore advanced data validation techniques to get a better sense of what to look for here.
An Evaluation Checklist For Your Shortlist
As you start to narrow down your options, it’s time to get granular. Use a detailed checklist to compare your shortlisted tools side-by-side. You need to go beyond the glossy marketing brochures and ask vendors direct questions about how their tool will actually perform inside your unique environment.
Key Questions to Ask Vendors:
- Integration Capabilities: How well does it play with our existing tech stack? We need to know if it connects seamlessly with our core systems like Salesforce , SAP , or Marketo. Are the connectors pre-built or will they require custom development?
- Scalability: We need to plan for the future. Can the tool handle our projected data volume growth over the next three to five years without performance grinding to a halt?
- Automation and Rules Engine: How easy is it for our non-technical business users to create and manage data quality rules? We need to understand how much of the cleansing and monitoring work can be automated.
- Total Cost of Ownership (TCO): What’s the full story on cost, beyond the initial licence fee? Be sure to ask about implementation fees, training requirements, ongoing maintenance, and any extra charges based on data volume or the number of connectors.
Choosing a data quality tool is less about the software itself and more about the business outcome you want to achieve. The right solution is one that becomes an invisible, automated part of your daily operations, quietly ensuring that every decision is based on information you can trust.
Comparing Data Quality Tool Approaches
A final, crucial decision point is whether to go for a dedicated, “best-of-breed” data quality tool or to use the DQM features that are already built into a larger data platform you might own, like an ETL tool or a Master Data Management (MDM) suite. Each path has its own distinct advantages and trade-offs.
This table breaks down the key differences to help you decide which approach aligns better with your organisation’s needs and strategy.
| Feature | Standalone DQM Tools | Integrated Data Platforms |
|---|---|---|
| Specialisation | Offers deep, highly advanced features for specific, complex tasks like fuzzy matching or address verification. | Provides good, general-purpose capabilities, but might lack the specialised depth needed for niche requirements. |
| Implementation | Generally faster to implement for a single, targeted problem. You can get a specific solution up and running quickly. | Can be part of a larger, more complex platform implementation, which may take more time and resources. |
| Cost | The initial cost for one tool is potentially lower, but the costs of licensing and managing multiple tools can add up. | Higher upfront cost for the entire platform, but the data quality features are often included in the package. |
| Integration | May require more custom development and effort to integrate smoothly across your entire technology stack. | Natively integrated with other components on the same platform, ensuring smoother internal data flows. |
Ultimately, the choice depends on your specific situation. If your organisation is grappling with a severe or highly specialised data quality problem, a standalone tool often provides the powerful, focused functionality you need to fix it. On the other hand, if you’re already investing in a comprehensive data management platform, its built-in DQM module might be perfectly sufficient—and a more cost-effective choice in the long run.
The Future of Automated Data Quality with AI

The next chapter in data quality management isn’t about working harder; it’s about working smarter. The future is being written by automation powered by Artificial Intelligence (AI) and Machine Learning (ML). This isn’t just a minor upgrade. It’s a fundamental shift, transforming data quality from a reactive, manual chore into a proactive, intelligent system that anticipates and resolves issues before they can ripple through your business.
Think of traditional data quality checks as a simple burglar alarm. It’s useful, but it only goes off after someone has already broken in. By then, the damage is done. An AI-powered approach, on the other hand, is like a full security team. It analyses patterns, predicts threats, and reinforces weak spots to prevent the break-in from ever happening. This is the new standard for safeguarding your most valuable asset: your data.
As we look ahead, the evolution of core AI processing systems will be the engine driving automated data quality. More powerful systems mean more sophisticated algorithms, pushing the boundaries of what’s possible for DQM.
Shifting From Reactive to Proactive
The heart of this change lies in a few key AI-driven technologies. Each one directly addresses a weakness in old-school data management, turning painstaking manual work into automated, self-improving functions.
AI-Powered Anomaly Detection: Instead of waiting for pre-set rules to catch known errors, AI models learn the normal rhythm and relationships within your data. They can then instantly spot anomalies—subtle deviations that signal a quality issue—the moment they appear, even if it’s a problem you’ve never encountered before.
Self-Tuning ML Algorithms: Machine learning can automatically refine your data cleansing rules. By analysing the results of past fixes, the system learns what “good” data looks like for your specific business context. Over time, it adjusts its own logic to become more accurate and efficient.
Natural Language Processing (NLP): So much business data is unstructured text: customer reviews, support emails, social media comments. NLP algorithms can dive into this chaos to interpret, structure, and standardise the information, extracting key details and sentiment to make it usable and consistent.
The real power of AI in data quality is its ability to learn and adapt. It moves an organisation from a state of periodic data clean-ups to one of continuous, automated data integrity.
The Impact on Decision Making
This intelligent automation doesn’t just mean cleaner databases. It fundamentally improves an organisation’s ability to act on its data with genuine confidence. When you can trust your data at every stage, from initial entry to final analysis, the entire business intelligence ecosystem becomes stronger. This builds a rock-solid foundation for more reliable reporting, more accurate forecasting, and ultimately, smarter strategic moves.
The capacity to make swift, accurate decisions is what separates market leaders from the rest. To see how trustworthy data fuels better business outcomes, you can explore our detailed guide on data-driven decision-making. By automating the foundational layer of data quality, companies can free up their people to focus on high-value analysis and innovation, knowing their data is consistently reliable.
Answering Your Top Data Quality Questions
Even with a solid plan and the right tools, putting a data quality management program into action always throws up some practical questions. Figuring out who’s in charge, how to justify the cost, and what roadblocks to expect can be the difference between a stalled project and a successful, self-sustaining business function. Let’s tackle some of the most common questions we hear from organisations starting their DQM journey.
Who Should Own Data Quality in an Organisation?
This is a classic question, and the answer isn’t as simple as pointing to one person. While a Chief Data Officer or a central data governance team might spearhead the initiative, real ownership is a shared responsibility. The best DQM programs create a culture where accountability is spread logically across the business.
Think of it as a strategic partnership. The business units—like sales, marketing, or finance—are the ultimate data owners. They’re the ones who live and breathe this information every day, so they know its context, its business impact, and what “good” actually looks like for their specific needs. At the same time, the IT department acts as the technical steward , looking after the systems, databases, and pipelines that store and move all that data.
This dual-ownership model is crucial. It stops data quality from being dismissed as just another “IT problem” and embeds it where it belongs: as a core business responsibility.
How Can I Prove the ROI of a Data Quality Project?
This is where the rubber meets the road. To prove the return on investment, you have to connect your cleanup efforts to real, tangible business outcomes. It’s not enough to just report that the data is “cleaner”; you need to show exactly how that newfound cleanliness drives financial gains or makes the business run smoother.
The key is to benchmark your key metrics before you start. This gives you a clear “before-and-after” snapshot to showcase your success. Focus on improvements you can actually count, such as:
- Reduced Operational Costs: Tally up the savings from things like eliminating returned mail, cutting wasted marketing spend on invalid contacts, or avoiding hefty compliance fines.
- Increased Revenue: Can you measure the uplift in sales from a marketing campaign that was better targeted thanks to accurate customer data? That’s pure ROI.
- Improved Efficiency: Track the hours your team gets back when they no longer have to manually fix data entry errors or chase down missing information.
The biggest initial challenge is often not technical, but cultural. Getting buy-in from across the organisation and shifting the mindset from viewing data quality as an ‘IT problem’ to a ‘business priority’ is the first and most critical hurdle.
So, how do you overcome that cultural resistance? Start small. Pick a single, high-impact project where bad data is causing obvious and painful problems. Fix it, and then shout about the value you delivered. A quick, decisive win like this builds the momentum and political capital you need to roll out a much broader, organisation-wide program.
At Osher Digital , we specialise in creating the automated data processing and system integrations that are the bedrock of excellent data quality management. Discover how our services can help you build a foundation of trusted data to drive efficiency and growth.
Last updated on July 1, 2026
Continue Reading
View all
What Is Data Warehousing? A Simple Guide for Humans
Curious about what is data warehousing? This guide explains core concepts, architectures, and real-world benefits in simple terms for modern business.
Nov 1, 2025

Data Analytics: The Four Types and When to Use Each
Data analytics turns raw business data into decisions. The four types explained, the tools that earn their place, and how to start without a data team.
Aug 27, 2025

Unlocking Financial Reporting Automation in Australia
Discover how financial reporting automation transforms Australian businesses. Learn to implement automation for greater efficiency, accuracy, and compliance.
Jul 30, 2025
Sick of reading about automation?
Book a free 15-minute intro call. We’ll talk through what you’re trying to automate and whether we’re a good fit.