Your Data Migration Strategy Playbook
Build a successful data migration strategy with our expert playbook. Learn to plan, execute, and validate your migration for seamless, risk-free results.
By Matthew Clarkson · November 1, 2025

A solid data migration strategy is much more than just a plan to move data from A to B. Think of it as a detailed blueprint for a complex operation. It’s a process that starts with deep discovery and careful planning, moves through execution, and finishes with rigorous validation. The ultimate goal? To ensure your data isn’t just moved, but remains secure, accurate, and completely usable in its new home.
Building Your Foundational Data Migration Strategy

From experience, I can tell you that a data migration project is won or lost long before a single byte of data is transferred. This foundational planning phase is what separates a smooth, predictable transition from a chaotic, budget-bleeding disaster. It’s about getting beyond simple checklists and developing real strategic foresight to build a plan that can scale and head off problems before they start.
This early work is all about defining the ‘why’ that drives the entire project. Without sharp, clear business objectives, the whole initiative lacks an anchor, and every decision that follows—from choosing tools to designing tests—is made in a vacuum.
Defining Clear Business Objectives
Let’s be clear: your migration isn’t just a technical task; it’s a business initiative. So, the first question must be, “Why are we really doing this?” The answer needs to be specific and measurable. Vague goals like “improving efficiency” simply won’t cut it.
You need to aim for crystal-clear outcomes. For example:
- Cost Reduction: “Our goal is to reduce annual data storage and maintenance costs by 25% by moving from on-premises servers to a cloud data warehouse.”
- Performance Improvement: “We need to decrease customer data retrieval times by 40% to support our new real-time analytics platform.”
- System Consolidation: “The project will decommission three legacy CRM systems, consolidating them into a single source of truth to kill data silos and boost reporting accuracy.”
Having concrete objectives like these gives your team a finish line and provides clear benchmarks to measure success against.
Conducting a Comprehensive Data Audit
Before you can map out the journey, you have to understand the terrain. A thorough data audit gives you that complete picture of your data landscape—where it lives, its quality, its structure, and all its hidden dependencies. I’ve seen too many projects stumble because this step was rushed. Assumptions made here can lead to spectacular failures down the line.
Start by inventorying every single data source involved. For each one, you need to analyse its current state with a critical eye. It’s a sobering fact that, on average, organisations find 22% of their data is exposed to all employees. That’s a massive risk you have to address before you migrate, not after.
A critical mistake I see time and again is underestimating the complexity of existing data. It’s not uncommon for teams to discover “shadow data”—forgotten databases, undocumented file shares, or redundant backups—only after the migration is underway. This inevitably causes significant delays and scope creep.
Your audit is also the perfect time to identify stale or obsolete data. Getting rid of this ROT (Redundant, Obsolete, Trivial) data cleans up your migration scope, saves a bundle on storage costs, and significantly reduces your overall risk profile.
Assembling Your Cross-Functional Team
A data migration is never just an IT project. True success demands a cross-functional team, pulling in people from across the business to ensure everyone is aligned and invested in the outcome.
At a minimum, your core team should include:
- IT and Infrastructure Specialists: The technical experts who manage the source and target systems.
- Business Analysts: The crucial translators who turn business needs into technical specifications.
- Data Owners: The subject matter experts who truly understand the data’s context and business value.
- Compliance and Security Officers: The guardians who ensure the migration meets all regulatory requirements and security policies.
This kind of collaboration ensures all angles are covered. For instance, your strategy needs to be forward-thinking enough to handle large-scale external pressures. The Australian Treasury recently had to increase its net migration forecast from 260,000 to 340,000 for a fiscal year due to strong labour market demands. This kind of demographic shift has direct implications for data infrastructure, demanding strategies that can manage a sudden influx of new resident and worker data. You can read more about how population shifts impact data infrastructure to understand the broader context.
Choosing Your Migration Approach
Deciding on the right method for your data migration is one of the most critical calls you’ll make. This single choice has a direct line to your project’s cost, the downtime your business has to stomach, and the overall level of risk involved. Broadly speaking, you’re looking at two main philosophies: the ‘Big Bang’ and the ‘Trickle’ approach. Each has its place, and each comes with its own set of trade-offs.
A ‘Big Bang’ migration is as dramatic as it sounds. You move every last piece of data from the source to the target system in one fell swoop. This usually means taking the source system completely offline and executing the entire transfer over a condensed timeframe, like a long weekend or a public holiday.
The allure here is its straightforward nature and speed. Because it all happens at once, you avoid the headache of running and synchronising two systems simultaneously. This cuts down on technical complexity and can seriously shorten the project’s overall timeline.
When to Consider a Big Bang
The ‘Big Bang’ approach often makes perfect sense for smaller organisations or isolated departments that can absorb a planned outage. Think of a retail business scheduling its migration for a quiet weekend. The impact on day-to-day sales and operations is kept to a minimum.
But here’s the catch: all your risk is bundled into that one event. If something goes sideways during that tight migration window, the failure is absolute, and your only option is a complete rollback. There’s simply no margin for error, which puts enormous pressure on your testing and validation work beforehand. You have to be utterly confident in your plan for this to work.
Understanding the Trickle Approach
On the other side of the coin, a trickle migration (sometimes called a phased migration) is a much more gradual affair. Instead of a one-shot transfer, you move data across in smaller, more manageable pieces over an extended period. Throughout this time, your old legacy system and the new target system are both live and running in parallel.
The biggest win with this method is risk management. By migrating incrementally, you can spot and resolve issues with a small batch of data before committing to the rest. This drastically lowers the potential blast radius of any single failure. For a 24/7 operation like a financial service or a critical healthcare system where even a few seconds of downtime is unthinkable, the trickle approach is often the only viable path.
The trade-off, however, is complexity. Keeping two systems perfectly synchronised requires a rock-solid coexistence strategy and some pretty sophisticated tooling to maintain data consistency. It’s a longer, and often more expensive, journey that demands meticulous planning. This is especially true when you’re grappling with the kind of complex data dependencies we cover in our guide to legacy system migration strategy.
This decision tree gives a great visual breakdown of how different factors—like the complexity of your source system, the sheer volume of data, and system compatibility—should guide your choice.
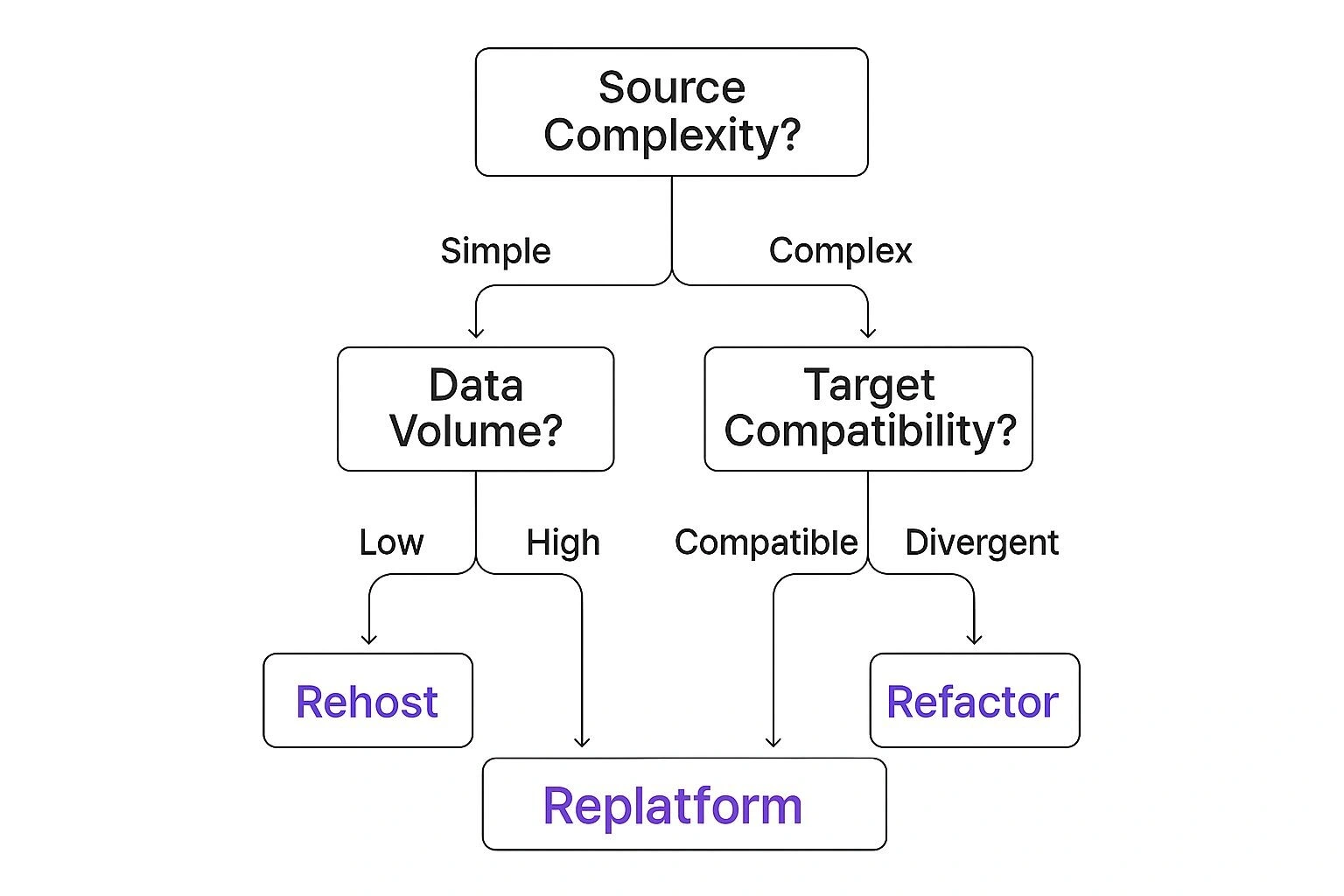
As you can see, the more complex your environment and the larger your data volume, the more the strategic pendulum swings away from the high-stakes ‘Big Bang’ and towards the more controlled ‘Trickle’ method.
Making the Right Choice for Your Business
To help clarify which path is right for you, let’s compare the two approaches side-by-side. This table breaks down the key factors to consider.
Comparing Big Bang vs Trickle Migration Approaches
| Factor | Big Bang Migration | Trickle Migration |
|---|---|---|
| Project Duration | Short and concentrated | Long and extended |
| Risk Profile | High-risk, single point of failure | Lower risk, distributed over time |
| Downtime | Requires a complete system outage (hours/days) | Minimal to zero downtime |
| Complexity | Simpler to manage; no parallel systems | Highly complex; requires data synchronisation |
| Cost | Generally lower upfront cost | Higher cost due to longer duration and tools |
| Rollback Plan | Must roll back the entire migration if it fails | Can roll back individual data chunks |
| Best For | Smaller data volumes, non-critical systems, organisations that can tolerate downtime | Large datasets, 24/7 operations, complex environments, mission-critical systems |
Ultimately, there’s no single “correct” answer. The right choice is the one that aligns with your organisation’s specific context and its tolerance for risk, downtime, and complexity.
A crucial question to ask your stakeholders is this: “What is the real business cost of our systems being down for 8 , 24 , or 48 hours?” The answer will often point you directly to the most appropriate data migration strategy.
By weighing the speed of a ‘Big Bang’ against the safety of a ‘Trickle’ migration, you can make an informed decision. A careful analysis of your data volume, system complexity, and business continuity needs will empower you to pick the strategy that gets your data to its new home safely and effectively.
Executing a Workload-Aware Migration

Now that you’ve chosen a migration approach, it’s time to get into the technical nitty-gritty. For modern applications, particularly those running in the cloud, simply shovelling data from one place to another just won’t cut it. The real measure of success for your data migration strategy is whether you can maintain—or ideally, improve—system performance after the switch. This demands a workload-aware approach, ensuring the new system can take a punch during peak operational hours without crumbling.
Think of this phase less as a data transfer and more as orchestrating a high-performance transition. It’s about deeply understanding how your data is actually used in the real world. This is non-negotiable for systems where a performance dip is catastrophic, like in finance or e-commerce.
Optimising for Performance and Load Balancing
A truly workload-aware migration looks at the complex web of relationships between different data components and how applications access them. It’s about making sure that data that’s frequently accessed together stays together in the new environment. This minimises latency and keeps throughput high—a far more sophisticated game than a standard “lift and shift”.
Take a busy e-commerce platform, for instance. Customer order data, inventory levels, and shipping information are in a constant, rapid-fire dialogue. A workload-aware strategy analyses these transactional patterns and physically organises the data in the target system to mirror this activity. The goal is to design out the bottlenecks before they ever have a chance to form.
Recent academic work has pushed this concept even further. Research from the University of Melbourne outlines strategies that use compressed hypergraph-based models to map out workload networks. By applying multi-criteria matching (MCM), these methods can balance loads and boost throughput, which is essential for any system running demanding transactional benchmarks. You can discover the full research on workload-aware data migration to see how these advanced strategies also support data consistency and slash downtime.
Scripting and Data Transformation
The real engine room of the execution phase is the set of scripts and processes that handle the extract, transform, and load (ETL) work. Let me be clear: these are not generic, off-the-shelf scripts. They have to be purpose-built for your specific migration, designed to navigate the unique quirks and complexities of your data.
Your migration scripts have a few critical jobs:
- Data Extraction: Pulling data from the source system efficiently, causing minimal disruption to live operations.
- Complex Transformations: Reformatting data to fit the new system’s schema. This isn’t just changing data types; it can involve merging or splitting fields, or enriching data with information from entirely different sources.
- Data Loading: Carefully inserting the transformed data into the target system, making sure to respect all dependencies and maintain integrity.
For example, I’ve seen countless projects involving moving customer records from a legacy system where the full address is just a single block of text. The new CRM, however, wants it neatly broken down into Street, Suburb, State, and Postcode. Your transformation script has to be smart enough to parse that old address field, accurately split it into four distinct components, and gracefully handle every weird variation and error in the source data.
A common pitfall I’ve seen derail projects is underestimating the “T” in ETL. The transformation stage is often the most time-consuming and error-prone part of the entire execution. A single flawed rule in a script can corrupt thousands of records, so meticulous, almost obsessive, testing is non-negotiable.
Implementing Bulletproof Error Handling
No migration is perfect. I’ve been doing this a long time, and I can tell you that even the best-laid plans will hit snags. The difference between a successful project and a messy failure often comes down to the quality of the error handling and logging. Your execution plan must have a robust framework for dealing with the unexpected.
This framework should include:
- Detailed Logging: Every single action your scripts take needs to be logged. You need to know which records were processed, what transformations were applied, and whether the operation succeeded or failed.
- Error Queues: When a record fails to migrate (maybe due to a data validation error), it shouldn’t grind the entire process to a halt. The script should shunt it into a separate error queue for later analysis and manual remediation.
- Automated Alerts: Your team can’t be everywhere at once. Set up automated alerts for critical errors, like high failure rates or specific error types, so they can intervene quickly.
By planning for failure and building the mechanisms to manage it, you ensure that minor issues don’t cascade into major project delays. This kind of technical diligence is what ensures your new system not only has the right data but is primed to outperform its predecessor from day one.
Getting Data Quality and Timing Right
A data migration isn’t just about moving information from A to B. Let’s be honest, that’s the simple part. The real challenge, where most projects get bogged down, is ensuring the data that lands in your new system is clean, accurate, and trustworthy. This is especially true when you’re pulling from multiple legacy systems, each with its own quirks and reporting delays.
You’re about to face the messy reality of enterprise data. When you start consolidating information from different sources, you’ll find a bit of everything: conflicting formats, duplicate customer records, and just plain wrong entries. Trying to build on top of that is like pouring a new foundation on shaky ground—it’s just asking for trouble down the line.
Throughout this entire process, it’s also vital to have robust cybersecurity and data protection measures in place. You need to safeguard sensitive information from any potential exposure or corruption as it moves between systems.
Dealing with Data Cleansing and Transformation
First things first, you need to get your hands dirty with data cleansing. This isn’t just running a quick spell-check. It’s a deep, methodical process of finding and fixing all the errors and inconsistencies before they have a chance to contaminate your shiny new system.
I’ve seen this play out time and again. The process usually boils down to a few key activities:
- Standardising Formats: Getting all your data to speak the same language. Think about making sure all dates, addresses, and phone numbers follow a single, consistent format.
- De-duplicating Records: This is a big one. You’ll need to hunt down and merge (or delete) duplicate entries for the same customer, product, or transaction.
- Validating Data: Checking your data against your own business rules. A classic example is verifying that a postcode actually exists within the state it’s listed under.
This is also where data transformation becomes critical. You might need to break a single “Full Name” field from an old database into separate “First Name” and “Last Name” fields for the new platform. Every one of these transformation rules needs to be carefully scripted and tested to make sure you don’t lose or misinterpret data along the way. For a deeper dive, our complete guide covers several effective data validation techniques you can put into practice.
Handling Time Delays and Lag-Aware Processes
Data quality isn’t just about being correct; it’s also about being current. The reality is that some data, particularly from third-party or government sources, comes with built-in reporting delays. Your migration plan has to account for this. You simply can’t treat all your data as if it represents one perfect snapshot in time.
A fantastic real-world example of this is how the Australian Bureau of Statistics (ABS) estimates interstate migration. They use Medicare change-of-address data, but they know people don’t always update their details the moment they move. To fix this, the ABS methodology intentionally lags the Medicare data by three months. This gives them a far more accurate picture of what’s actually happening.
This approach teaches us a crucial lesson: your migration strategy must be “lag-aware.” Instead of pretending everything is up-to-the-minute, you have to build processes that can accommodate and correct for these known delays.
In practice, this might mean setting up reconciliation workflows that run periodically after the main migration, updating records as more timely information trickles in.
Locking in Long-Term Data Integrity with Governance
The job isn’t finished once the last byte of data has been moved. Without strong data governance, that pristine, organised data you just migrated will slowly degrade. It’s a concept we call “data decay,” and it’s a silent killer for many organisations. In fact, some studies suggest poor quality data can cost companies up to 25% of their revenue.
To stop this from happening, you need to establish clear data governance policies the moment the migration is complete.
These policies should spell out:
- Data Ownership: Who is ultimately responsible for the quality of specific data? Assigning clear owners to individuals or teams is non-negotiable.
- Quality Standards: Define what “good” looks like. Set measurable standards for data accuracy, completeness, and timeliness.
- Maintenance Processes: Create ongoing procedures for data cleansing and validation to maintain that high quality for the long haul.
By making governance part of your daily operations, you shift from a one-off clean-up project to a sustained culture of data excellence. This is how you ensure the hard work you put into the migration delivers real, lasting value.
Validating Success With Rigorous Testing
 After all the meticulous planning and execution, how do you actually prove your data migration strategy was a success? The proof isn’t a simple “migration complete” message. It’s earned through rigorous, multi-layered testing. This is your final quality gate, the last checkpoint before you can confidently turn off the old system for good.
After all the meticulous planning and execution, how do you actually prove your data migration strategy was a success? The proof isn’t a simple “migration complete” message. It’s earned through rigorous, multi-layered testing. This is your final quality gate, the last checkpoint before you can confidently turn off the old system for good.
A solid testing plan isn’t a single event; it’s a series of checkpoints, each designed to verify different aspects of the migration. I’ve seen too many projects rush this stage, and it almost always ends in post-launch chaos. Users suddenly discover data is missing, corrupted, or that the new system grinds to a halt under real-world pressure. It’s a costly and entirely avoidable mistake.
A Multi-Layered Testing Framework
A comprehensive testing framework validates everything from the smallest data point right up to the entire end-to-end user experience. It needs to involve several distinct stages, each with a specific focus.
Think of it like building a house. You don’t just inspect the finished structure. You check the foundation (unit testing), the plumbing and electrical systems (integration testing), and its ability to withstand a storm (performance testing) long before anyone thinks about moving in.
This layered approach is your best bet for ensuring that by the time you reach final validation, you’ve already caught and fixed most of the issues. It makes the final sign-off a much smoother, more confident process.
Core Testing Stages and What to Look For
Each stage of testing serves a unique purpose, systematically building confidence in the migration’s success. Your plan should move methodically through these core stages to make sure nothing is missed.
Here’s a breakdown of the essential tests I always recommend:
Unit Testing: This is where you get granular. You’re testing individual data transformations and mapping rules at the field level. For instance, if you’re migrating customer addresses, a unit test would confirm that a single-line address field from the source system was correctly parsed into
Street,Suburb,State, andPostcodein the new system without losing or corrupting any information.System Integration Testing (SIT): Now you zoom out. SIT checks that the newly migrated data works correctly within the target system and plays nicely with any connected applications. It’s all about validating the end-to-end functionality of core business processes. Can a sales rep actually create a quote using the migrated customer and product data?
Performance and Load Testing: This is where you really put the new environment through its paces. You simulate peak user loads to see how the system responds under pressure. Does data retrieval slow to a crawl when 500 users are logged in at once? This is how you validate that the new system meets the performance benchmarks you defined right back at the start.
User Acceptance Testing (UAT): This is the final—and arguably most critical—stage. You hand the keys over to real business users and let them perform their daily tasks in the new system. Their job is to confirm that the system meets their business needs and that the data is accurate, complete, and genuinely usable from their perspective.
A common pitfall is treating User Acceptance Testing as a mere formality. It’s not. In my experience, it’s your last and best line of defence. Providing your business users with clear test cases and, crucially, dedicated time for UAT is essential for catching the kind of real-world issues that technical teams might overlook.
To ensure your testing framework is robust, it helps to lean on established industry standards. For a broader look at ensuring data integrity and functionality, it’s worth exploring general software testing best practices.
The Go-Live Decision and Post-Migration Monitoring
Once all testing phases are complete and signed off—especially UAT—you’re ready for the go-live decision. This shouldn’t be a casual chat; it needs to be a formal process involving all key stakeholders who review the validation reports and give their final, informed approval.
But the work doesn’t stop at cutover. Post-launch monitoring is crucial. For the first few weeks, your team must keep a close eye on system performance, error logs, and user feedback to quickly jump on any unforeseen issues.
Only after a period of stable operation, usually a full business cycle, should you formally decommission the legacy systems. This final step is an essential part of a well-defined project, and it’s often managed within a larger framework. To see how this all fits into the bigger picture of your organisation’s data governance, you can learn more about creating a complete data management plan.
Frequently Asked Questions About Data Migration
https://www.youtube.com/embed/S7HTsuWz_2U
Even with the most rock-solid plan, questions always pop up during a data migration. I’ve been in the trenches with enough of these projects to know which ones keep teams up at night. Let’s tackle some of the most common queries I hear, with straight answers to help you sidestep any potential headaches.
A well-thought-out data migration strategy should answer most of these from the get-go, but having a quick reference like this is invaluable for keeping the project moving and stakeholders confident.
How Long Does a Data Migration Typically Take?
This is the big one, and the only honest answer is: it depends entirely on the scope of your project. There’s just no universal timeline.
For a small business moving a single database to the cloud, a ‘Big Bang’ migration might be done and dusted over a single weekend. It’s intense, but it’s fast.
On the other hand, a large enterprise with petabytes of data tangled up in complex, interconnected legacy systems will almost certainly need a ‘Trickle’ migration. This is a much more deliberate, phased approach that could stretch over several months, or even a year. The goal here is zero downtime and absolute data integrity.
The timeline really hinges on a few key factors:
- Data Volume: Simply, how much stuff are you moving?
- Data Complexity: How intricate are the data relationships, dependencies, and transformation rules?
- Migration Approach: Are you ripping the band-aid off with a ‘Big Bang’ or taking the slow and steady ‘Trickle’ path?
- Team Resources: Do you have the right people with the right skills available?
What Is the Biggest Risk in Data Migration?
While things like hardware failures or technical bugs are always on the radar, the risks that can truly cripple a business are prolonged, unplanned downtime and data corruption or loss.
These aren’t just technical problems; they’re business catastrophes. They can lead to huge financial losses, bring operations to a grinding halt, and do serious damage to your company’s reputation.
Just picture an e-commerce platform where customer order histories get scrambled or deleted during a migration. The fallout is immediate and severe, impacting everything from customer support to financial reporting. You don’t manage this risk by crossing your fingers; you manage it with a meticulous strategy that includes tough testing, exhaustive validation, and a rollback plan you’ve practised.
Your rollback plan is your ultimate safety net. It needs to be just as detailed and tested as your migration plan itself. The ability to quickly and cleanly revert to the source system if disaster strikes isn’t a nice-to-have—it’s non-negotiable for a secure migration.
How Do You Ensure Data Quality After Migration?
Good data quality isn’t something you check for at the end. It’s a discipline you practice throughout the entire project.
It all starts long before you move a single byte of data, with pre-migration data profiling and cleansing. This is your chance to find and fix all the inconsistencies, duplicates, and errors lurking in your source system. During the migration itself, you should have validation rules and scripts running to check data as it’s transferred.
Once the data is in its new home, the real validation work begins. This involves a full-scale data reconciliation , where you systematically compare data samples from the source and target systems to confirm everything matches perfectly. Automated tools are a lifesaver here, capable of checking millions of record counts and doing field-by-field comparisons.
Finally, you need to establish long-term data governance policies. This is what stops the slow decay of data integrity over time and keeps your new system clean and reliable.
How Much Data Should We Actually Migrate?
It’s a common mistake to assume that everything has to come along for the ride. The truth is, many organisations are sitting on a mountain of ROT—that’s R edundant, O bsolete, or T rivial data. In fact, some analyses show that 22% of a company’s data can be exposed to all employees, a lot of which is probably stale and untouched.
A crucial part of your initial strategy should be to identify this dead weight before the migration even starts. By archiving or securely deleting it, you can slash the scope of your project. This doesn’t just cut down on migration costs and complexity; it also shrinks your security risk profile in the new environment.
What’s the Best Way to Handle Business Logic in the Old System?
This is a sneaky one. Critical business logic is often buried deep inside legacy systems, sometimes in poorly documented stored procedures or ancient application code. If you just lift and shift the data without accounting for this logic, you’re setting yourself up for failure.
The most effective way I’ve seen this handled is by using automated code conversion tools as an integral part of the migration. These tools can analyse the old, clunky code and translate it into a modern equivalent for your target platform. In some projects, this has saved developers over 80% of their development time.
This approach ensures vital business rules aren’t lost in translation or misinterpreted. It transforms what could be a high-risk, manual slog into a far more predictable and automated process.
Ready to modernise your operations but worried about the risks of getting your data from A to B? Osher Digital specialises in building and executing robust automation and data strategies that minimise downtime and deliver real value. We get our hands dirty with the complexities of system integrations and data processing, so you can focus on scalable growth.
Visit us at https://osher.com.au to learn how we can ensure your next migration is a success.
Last updated on July 1, 2026
Continue Reading
View all
A Simple Guide to Data Integration
Imagine your business data is a collection of puzzle pieces, but they’re all stored in different boxes. Your sales figures are in one box, customer feedback is in another, and your stock levels are tucked away in a third. Data integration is the art of bringing all those scattered pieces together to reveal the complete […]
Dec 18, 2025

Customer Data Integration: Build a Unified View with Real-World Examples
Customer data integration is all about creating a single, trustworthy source of truth for every customer. It’s the process of pulling together information from all your scattered business systems, like your sales software, marketing platform, e-commerce site, and support desk, to build one complete picture. This makes sure everyone, from sales to support, is working […]
Dec 13, 2025

What is System Integration? A Quick Guide to Boosting Your Efficiency
System integration is all about connecting your different software and applications so they can share information and work together as one big, happy team. It’s about breaking down the digital walls between your departments so data can flow freely, automating tasks and making your whole business run a lot smoother. What is System Integration? I […]
Nov 15, 2025
Sick of reading about automation?
Book a free 15-minute intro call. We’ll talk through what you’re trying to automate and whether we’re a good fit.