What Is a Datalake and How Does It Fuel Modern AI?
A datalake is a central place designed to store a huge amount of raw data just as it is, holding it there until you need it for something specific. It’s like a massive, natural reservoir where you can pour all your business information… from neat spreadsheets to messy social media comments. You don’t have to […]
By Matthew Clarkson · November 2, 2025

A datalake is a central place designed to store a huge amount of raw data just as it is, holding it there until you need it for something specific. It’s like a massive, natural reservoir where you can pour all your business information… from neat spreadsheets to messy social media comments. You don’t have to clean it up first. This ‘store everything’ idea is the secret sauce for building genuinely smart AI systems.
So, What Exactly Is a Datalake?
It feels like ‘datalake’ is the new word on everyone’s lips, doesn’t it? One minute you’re talking about managing data, the next it’s all about lakes. But what does it actually mean for you? Let’s cut through the jargon and get to what matters.
Imagine your business data is water. For decades, we’ve built carefully constructed dams and canals (let’s call those data warehouses ) to channel filtered water to specific towns for specific uses. This approach is organised and super reliable, but it’s also pretty rigid. You can only use that water for the things you originally designed the system for.

A datalake is a completely different beast. It’s much more like a sprawling, natural reservoir.
Every single drop of data your organisation creates or collects flows into this lake, exactly as it is. There’s no pre-filtering. No changing things around. No structuring needed before it goes in. It all just gets poured in.
A Place for Everything and Anything
When we say everything, we mean everything. A datalake is built to handle every kind of data you can think of, letting it all sit together in one place. It’s not just for the neat and tidy stuff; a real datalake welcomes the messy, unstructured data that so often holds the most valuable clues.
This includes:
- Structured Data: This is your clean, organised data from your CRM, ERP, or finance systems. The easy stuff.
- Semi-Structured Data: Think of things like emails, CSV files, or web server logs. They have some internal organisation but don’t fit into a strict database format.
- Unstructured Data: Now this is where it gets really interesting. This is your social media posts, customer call recordings, video files, images, and real-time data from sensors.
This ‘keep everything’ approach is a huge shift in how businesses handle information. Instead of deciding beforehand what questions you might want to ask of your data, you just collect it all. You’re building a resource for the future.
The core idea is to create a single source of raw potential. It’s a place where future questions—the ones you haven’t even thought of yet—can be answered because you had the foresight to save the raw ingredients.
This is exactly why the datalake is so vital for any organisation with serious AI plans. AI models thrive on variety and volume. They need the raw, unfiltered truth of your business to learn, spot hidden patterns, and make smart predictions. You can’t train a powerful AI on a small, perfectly sanitised dataset; you need the whole, messy, wonderful reservoir to draw from.
How a Datalake Differs from a Data Warehouse
This is the question that always seems to come up, right? If you’ve spent any time with traditional data systems, you’ll know about the data warehouse. It’s all about structure. Getting your data perfectly cleaned, processed, and organised before it even gets in the door.
So, is a datalake just a newer, messier version of that? Not really.
They’re more like two different tools for two very different jobs. They both manage data, of course, but their whole philosophy is different. It’s the difference between a carefully curated library and a sprawling, unsorted attic full of potential treasures.

The Tidy World of the Data Warehouse
Let’s start with the library. A data warehouse is exactly that. A place where every piece of information has been carefully catalogued and put on a specific shelf.
When you walk into this library, you already know what you’re looking for. You have a clear question, like, “What were our total sales in Victoria last quarter?” The entire system is built to answer these kinds of known, structured questions with incredible speed.
This efficiency comes from doing all the hard work of cleaning and organising upfront. In technical terms, this is called schema-on-write. The structure (schema) is defined before any data is written to the warehouse. For a deeper look at this model, you can read our guide on what data warehousing is.
This approach is rock-solid for standard business reporting. It’s predictable. It’s reliable. But that rigidity can also be a weakness.
The greatest strength of a data warehouse is its structure. But that same structure becomes a limitation when you need to ask new, creative questions you didn’t think of when you first built it.
The Raw Potential of the Datalake
Now, let’s head up to the attic. This is your datalake. It’s a huge space filled with everything you’ve collected over the years. Old photos, letters, documents, receipts. At first glance, it looks like chaos.
But that’s the point.
A datalake doesn’t force you to impose order upfront. It uses the opposite approach, known as schema-on-read. This just means you figure out the structure later, at the moment you actually decide to use the data for something. You can pour everything in. Raw. Unfiltered. In whatever format it arrived in.
This flexibility is its real power. Sifting through that “messy” attic, you might find an old letter that gives crucial context to a photo, revealing a story you never knew existed. That’s what a datalake lets you do. It gives data scientists the freedom to explore everything, connecting the dots between things that seem unrelated.
They could, for instance, mix customer support emails (unstructured text) with sales figures (structured numbers) and social media sentiment (semi-structured data) to uncover the real reason a new product isn’t selling. You could never plan for that kind of deep, exploratory work inside the rigid walls of a traditional data warehouse.
Datalake vs Data Warehouse A Quick Comparison
To really see the difference, it helps to put them side-by-side. The table below breaks down their fundamental characteristics.
| Characteristic | Datalake | Data Warehouse |
|---|---|---|
| Data Type | Stores everything. Raw, unstructured, semi-structured, and structured data. | Primarily stores processed and structured data that is ready for analysis. |
| Schema | Schema-on-read. The structure is applied when you pull the data out. | Schema-on-write. Data must be structured before it’s loaded. |
| Best For | Exploratory analytics, data science, and machine learning model training. | Standard business intelligence, reporting, and answering known questions. |
| Users | Data scientists, advanced analysts, and AI developers who need raw data. | Business analysts and managers who need clean, aggregated reports. |
In the end, it’s rarely a case of choosing one over the other. Most modern organisations are realising they need both. The data warehouse becomes the reliable engine for running the day-to-day business with consistent reports, while the datalake acts as the innovation lab, fuelling the advanced analytics and AI projects that will shape the future.
The Engine Room of Australia’s AI Revolution
So why is the term data lake suddenly everywhere, from boardrooms in Sydney to tech hubs in Melbourne? The answer’s pretty simple. Modern AI is incredibly hungry, and its favourite meal is a vast, messy, and diverse banquet of raw data.
You can’t build a sophisticated AI model on a few perfectly manicured spreadsheets. That’s like trying to teach a doctor about human health by only showing them a skeleton. To truly learn, AI needs the messy stuff. The context. The raw signals. The unfiltered reality of what’s going on. And that’s exactly what a data lake provides. It’s the foundational powerhouse for the next wave of Aussie innovation.
Why AI Thrives on Raw, Unstructured Data
Think about how we learn. We don’t just memorise isolated facts. We absorb information from conversations, experiences, and observing the world in its natural, often chaotic, state. AI models, especially those built for complex jobs like predicting machine failures or customer behaviour, work in a similar way.
They need to see the whole, unvarnished picture. A data lake is designed to store exactly that:
- Customer service call transcripts to understand how people really feel.
- Real-time sensor data from mining equipment to predict when it might break.
- Satellite imagery and weather patterns for better agricultural planning.
- Website clickstream data to see the complete, winding path a customer takes.
Feeding an AI model only the clean, final sales numbers from a data warehouse is fine, but it’s like reading a story with the middle chapters ripped out. The model misses the why. It can’t see the subtle clues and hidden connections buried in the raw data that a data lake carefully saves. It’s in that unfiltered chaos where real intelligence is often hiding.
A data lake doesn’t just hold data; it holds potential. It’s a training ground where AI can learn the complex, non-obvious patterns of your business, unlocking insights you could never have planned for.
This crucial relationship is fuelling a huge expansion of data infrastructure across the country. As Australian businesses dive deeper into AI, the need for the storage and processing power of a data lake is exploding. This isn’t just a trend; it’s a direct response to AI’s incredible appetite for data. In fact, Australia’s live data centre power capacity is forecast to grow from roughly 1.4 gigawatts (GW) in 2025 to 1.8 GW by 2028, largely to handle data-heavy applications like AI. You can dig into this infrastructure boom in more detail with CBRE’s analysis on Australian data centre demand.
Australian Industries Leading the Way
This isn’t some abstract theory just for the tech sector. It’s happening right now, creating real value across Australia’s biggest industries.
Take Western Australia’s resources sector. Major mining companies are channelling data from sensors on their haul trucks, drills, and processing plants into a central data lake. By letting AI loose on this raw stream of information, their models can predict mechanical failures days, or even weeks, in advance. We’re not talking about minor savings here… this is about preventing millions of dollars in operational downtime.
We see the same thing happening in agriculture. Farmers are now combining drone imagery, soil sensor readings, and long-range weather forecasts within a data lake. This allows AI algorithms to recommend hyper-specific irrigation and fertilisation schedules, boosting crop yields while saving precious water. The insights were always there, just scattered across different systems. The data lake was the missing piece that brought it all together for an AI to make sense of it all. From finance to logistics, the principle is the same: a data lake provides the fuel, and AI delivers the intelligence.
How to Avoid Creating a Data Swamp
Okay, let’s talk about the elephant in the room. The dreaded ‘data swamp’. It’s a real risk and something I’ve seen happen when a promising datalake project goes wrong. It’s what you get when your central data store becomes a chaotic, unregulated digital dumping ground.
Imagine just pouring all your data into a giant pool with no filters, no signs, and no one checking what goes in. It doesn’t take long for it to get murky. Soon you can’t find anything, you can’t trust the quality of what you pull out, and it becomes completely useless.
The good news? This is totally avoidable. It all comes down to smart planning from the very beginning.
Think Like a City Planner for Your Data
The best way to avoid a data swamp is to stop thinking of your datalake as just a massive storage bucket. Instead, think of it like planning a city. A working city isn’t a random collection of buildings. It’s designed with purpose. It has specific zones, clear roads, and rules that keep things orderly and efficient.
Your datalake needs that same kind of deliberate structure. This isn’t about being overly strict. It’s about making sure your data is easy to find, trustworthy, and, most importantly, actually useful.
Here’s a simple way I often think about it:
- The Raw Zone: This is your city’s main port. It’s where all the raw materials, your data, arrive directly from their sources, completely untouched and in their original state.
- The Processed Zone: Think of this as the industrial park. Here, data engineers take those raw materials, clean them up, standardise them, and get them ready for specific jobs.
- The Curated Zone: This is the city’s commercial and business district. It holds the high-quality, verified, and ready-to-use data that your business analysts and AI models will access for their projects.
This simple, zoned approach is a game-changer. It means you always have the original, untouched data to go back to, while also providing clean, reliable datasets for everyday work.
This diagram helps you see how a well-organised datalake sits right at the centre of your AI strategy, turning raw information into valuable intelligence.
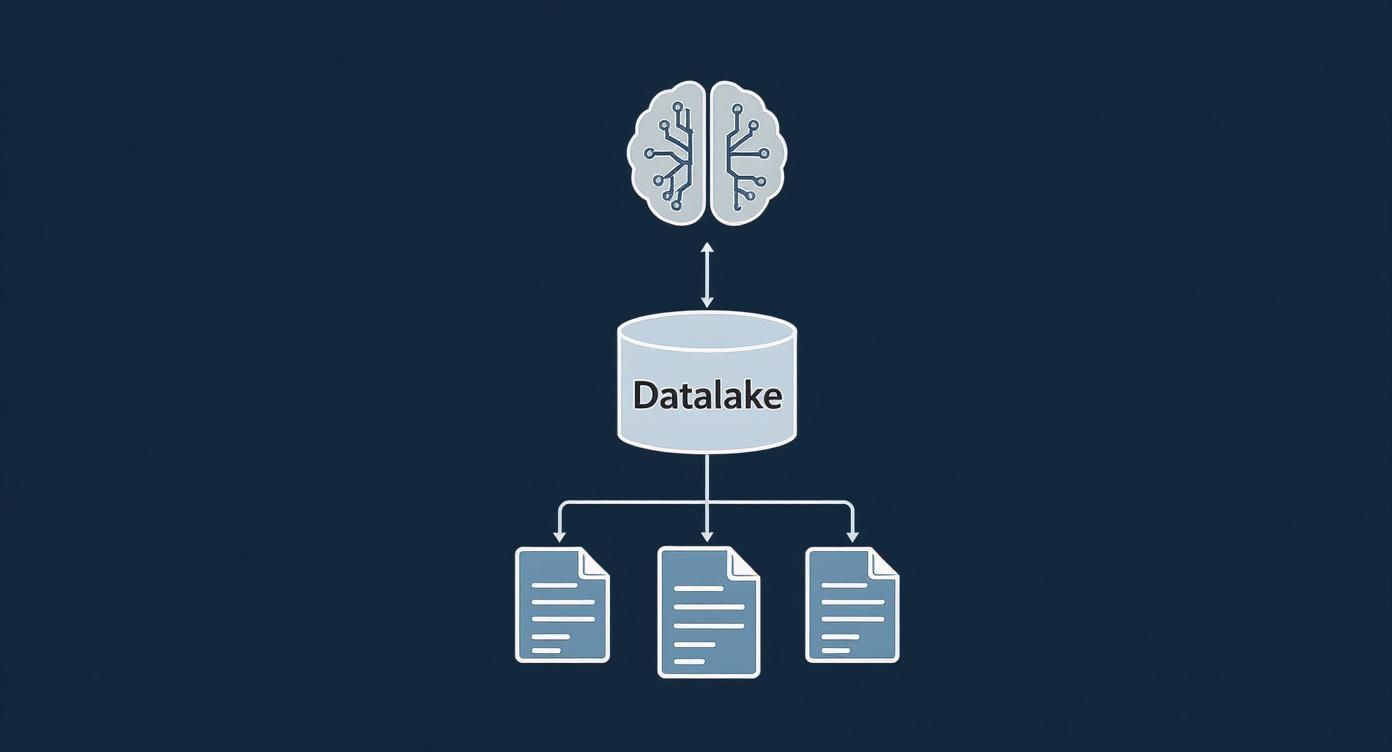
The key takeaway is that the datalake isn’t just storage. It’s the critical bridge that makes huge amounts of raw data accessible and usable for sophisticated AI systems.
The Rules of the Road: Data Governance
So, you’ve got your city plan. Now you need some rules of the road. This is where data governance comes in. I know it can sound a bit corporate and dry, but it’s really just about setting up practical rules for managing your data to keep it valuable and secure.
Effective governance is a huge topic, but a few core practices are non-negotiable for keeping your datalake pristine. We cover this in much more detail in our guide on what data governance truly involves, but here are the essentials.
- A Data Catalogue: This is your city map. It tells everyone what data you have, where it came from, who owns it, and what it means. Without a catalogue, your teams are basically wandering around blind.
- Metadata Management: If data is the raw material, metadata is the label on the box. It gives you crucial context… like when the data was created and its format. This makes it searchable and understandable.
- Access Controls: You wouldn’t give everyone the keys to every building in the city. Access controls make sure that only the right people can see or change specific datasets, which is vital for security and compliance.
Getting this right is becoming more critical than ever. The Australian data lake market is projected to grow at a huge 22.5% CAGR between 2025 and 2035, as more industries lean on AI. Interestingly, about 62.3% of that market in 2025 is expected to be on-premise, highlighting a strong local preference for data control due to sovereignty and security concerns.
You wouldn’t build a city without roads, maps, and laws. Applying that same logic to your datalake with a solid governance framework is the single most important step you can take to prevent a data swamp.
A crucial part of this is knowing what to keep and what to get rid of. Hoarding data forever is expensive and just creates clutter. Learning from these 7 data retention policy examples can help you build a smart strategy. It’s about being intentional with your data, not just building a digital mountain.
Real-World Examples of Data Lakes in Action
Theory is one thing, but let’s get into the good stuff. How are actual businesses using a data lake to do things that were simply impossible before? This is where the whole idea moves from a technical diagram to a genuine competitive edge.
It’s about connecting dots you didn’t even know were there. A data lake gives you the raw ingredients to cook up some seriously powerful insights.
Smarter Retail and E-commerce
Imagine you’re a retail company trying to figure out stock levels for next season. The old way involved looking at last year’s sales figures. It’s a decent starting point, but it’s like driving while only looking in the rearview mirror.
Now, picture this. You start pouring all sorts of data into a central data lake. We’re talking about:
- In-store foot traffic patterns from sensor data.
- Real-time social media trends and what people are talking about.
- Long-range weather forecasts for key locations.
- Website clickstream data showing what customers are browsing but not buying.
Suddenly, you can ask much smarter questions. Your AI models can sift through all this seemingly unrelated information and find connections. They might spot that a warm winter forecast combined with social media chatter about a certain colour means you should be stocking up on lightweight jackets, not heavy coats. This isn’t just managing inventory. It’s predictive commerce.
Predictive Maintenance in Resources and Manufacturing
This is a huge one, especially here in Australia. For a resources company, an unexpected equipment failure on a critical piece of machinery isn’t just an inconvenience. It can cost millions of dollars a day in lost production.
So, they use a data lake to get ahead of the problem. They collect a constant stream of raw data from thousands of sensors on their machinery, things like vibration levels, operating temperatures, and pressure readings.
By feeding this massive, continuous stream of data into AI models, they can detect tiny, almost invisible changes in performance that signal a potential failure is coming. It’s like a doctor spotting early symptoms before a major health crisis.
This allows them to schedule maintenance proactively, ordering parts in advance and avoiding catastrophic downtime. They’re moving from a reactive “fix it when it breaks” model to a predictive “fix it before it ever has a chance to break” one. It’s a total game-changer for how they operate.
This drive to connect physical operations with digital intelligence is fuelling huge investment in the infrastructure that supports a data lake. The Australian data centre storage market, which is the backbone for these solutions, is valued at about USD 2.97 billion in 2025 and is projected to hit USD 3.95 billion by 2030. This growth is directly linked to the rapid adoption of AI workloads and the expansion of cloud infrastructure. You can explore more about Australia’s data infrastructure growth on Mordor Intelligence.
Ultimately, these examples show that a data lake isn’t just about storing data. It’s about creating a playground for curiosity and innovation, giving you the ability to blend different sources of information to uncover insights that were previously hidden in plain sight.
Your First Steps into Building a Datalake
https://www.youtube.com/embed/-bSkREem8dM?feature=oembed
So, you’re sold on the idea. A data lake seems like the right move to power your future analytics and AI work. But where do you actually begin? It can feel like such a massive project, so large that it’s hard to know where to even start.
The secret is to resist the urge to do everything at once. Seriously. Forget about a huge, all-encompassing build for now. The most successful data lake journeys always start small, with a laser focus on a clear business purpose. This is your practical guide to taking that first step without getting overwhelmed.
Start with a Real Business Problem
Before you even look at a technology provider’s website, just step back. Ask one fundamental question: what specific, nagging business problem are you actually trying to solve? If you can’t answer this with absolute clarity, you’re probably heading down a long, expensive path that goes nowhere.
“We want to do AI” isn’t a business problem. It’s a wish. You need to get specific. Are you trying to:
- Reduce customer churn by spotting at-risk behaviours?
- Improve operational efficiency by predicting when machinery needs maintenance?
- Increase sales by delivering truly personalised marketing campaigns?
Pick just one. A single, high-impact problem that would make a real difference if you solved it. This becomes the North Star for your entire project.
Your first data lake project shouldn’t be about building the perfect, all-encompassing data platform. It should be about solving one specific business problem so well that everyone sees the value and wants more.
Assemble a Small, Focused Team
You don’t need a huge team to get this started. What you do need is a small, dedicated group with the right mix of skills. Typically, this means bringing together someone who understands the business problem inside and out, an engineer who can get the data flowing, and someone skilled in analysing it.
The successful setup and running of a data lake relies on solid data engineering principles. It’s not just about getting some storage space; it’s about building strong pipelines that reliably feed your lake. Getting this part right is foundational. If you want to dive deeper into the technical side, you can learn more about the crucial role of these connections in our guide to data integration best practices.
Run a Pilot Project
This is the most critical step of all. Don’t try to build the entire data lake in one go. Instead, launch a pilot project focused squarely on that single business problem you identified.
Your pilot should have three clear goals:
- Ingest a limited dataset: Only pull in the specific data sources you need to address your chosen problem.
- Prove the technology: Test your chosen cloud storage and processing tools on a manageable scale to see how they perform.
- Deliver a quick win: Produce a real insight or outcome that clearly shows the value back to the business.
Maybe you analyse six months of customer support tickets and sales data to pinpoint the top three reasons customers are leaving. It doesn’t need to be a complex predictive model on day one. It just needs to prove the concept works.
This approach dramatically de-risks the whole initiative. You learn valuable lessons, you build momentum, and you get the rest of the business genuinely excited about the possibilities. From that strong foundation, you can then expand your data lake, one valuable business problem at a time.
Frequently Asked Questions About Datalakes
Even after diving deep into the concept, a few common questions always seem to pop up as organisations get serious about building a datalake. It’s a big shift in how we think about data, so let’s tackle these questions head-on.
How Secure Is a Datalake?
This is often the first, and most important, question. The short answer is yes, a datalake can be incredibly secure, but that security doesn’t happen by accident. It has to be designed into the architecture from day one, not tacked on as an afterthought.
Think of it like building a bank vault. You don’t just put up four walls and a door; you build in layers of defence. For a datalake, this means strong encryption for data both at rest (while it’s stored) and in transit (as it moves between systems). It also requires fine-grained access controls , making sure that people can only see or change the data they’re explicitly authorised to. Modern cloud platforms give you a powerful set of tools for managing these layers, helping you keep your sensitive information locked down.
Do I Need Data Scientists to Use a Datalake?
While data scientists are certainly power users who love the raw, unfiltered data for building complex models, a well-designed datalake is a resource for the entire organisation. It shouldn’t be an exclusive playground for just a few people.
Remember those curated zones we talked about earlier? Once data has been processed, cleaned, and structured in those areas, it becomes hugely valuable for business analysts, product managers, and decision-makers. With the right self-service tools, they can explore the data, run queries, and build insightful reports without needing a deep technical background. The ultimate goal is to make data accessible to more people, not create another high-tech silo.
Can a Small Business Benefit from a Datalake?
Absolutely. It’s a common myth that datalakes are only for massive companies with endless budgets. Thanks to the pay-as-you-go pricing of cloud platforms like AWS, Azure, and Google Cloud, the barrier to entry is lower than ever.
A small business can start by creating a modest datalake to bring together information from a few key sources… say, their website analytics, accounting software, and social media channels. Even this simple setup can start revealing valuable patterns in customer behaviour or operational hiccups that were previously invisible. It’s not about the size of your company; it’s about having the ambition to make smarter, data-driven decisions.
Ready to stop just storing data and start turning it into your most powerful asset? At Osher Digital , we build the intelligent automation and data solutions that fuel real business growth. Let’s explore how a data lake can power your AI ambitions. Find out more at https://osher.com.au.
Last updated on July 1, 2026
Continue Reading
View all
AI Agency Software
We have productized our own internal AI agency software – administrate.dev
Jan 31, 2026

AI in Mining Uncovered: How Smart Tech Boosts Safety and Profit
Imagine having a partner for your operations team who never sleeps. A partner who can sift through endless streams of data from your drills, trucks, and sensors, spotting tiny clues that signal a million-dollar problem is just around the corner. That’s the real value of AI in mining. It is not about sci-fi robots; it […]
Jan 30, 2026

A Plain English Guide to AI in Logistics
Artificial intelligence in logistics is about giving your supply chain a brain. It is not about self-aware robots taking over the warehouse floor, but rather about using smart systems to make your entire operation more efficient, predictive, and resilient. Think of it as the ultimate co-pilot for your logistics team. It is an assistant that […]
Jan 22, 2026
Sick of reading about automation?
Book a free 15-minute intro call. We’ll talk through what you’re trying to automate and whether we’re a good fit.