AI Agents on OpenAI: The 2026 Stack
How we build production AI agents on OpenAI in 2026: the SDK choices, model picks, gotchas, and the times we reach for Claude or n8n instead.
By Matthew Clarkson · July 10, 2024

Updated May 2026. Rewritten with current model identifiers, the Agents SDK, AgentKit, and production patterns we have shipped in the last twelve months.
The shape of building AI agents on OpenAI changed more in the last year than in the two years before. The Assistants API is on its way out. The Agents SDK is the recommended path. AgentKit gives you a visual builder over the same primitives. The chat completions API is still alive and well for narrow use cases. If you last looked at this in early 2024, almost everything in your old code is the wrong starting point now.
We are Osher Digital, an automation consultancy in Brisbane. This is the reference document we hand to clients who ask “what does building on OpenAI actually look like in 2026?”. It covers the SDK choices, the model lineup, the working patterns we use, and the situations where we reach for Claude or n8n instead.
For background, our explainer on what an AI agent actually is covers the conceptual ground. For an alternative provider’s take, see building an AI agent with Claude, which uses the Anthropic SDK and is structurally similar.
What an agent is, in operational terms
An agent is a loop. The model receives a goal and a set of tools. It decides which tool to call, you call it, you feed the result back in, and the model decides what to do next. The loop continues until the model returns a final answer or hits whatever bound you set on it. Everything else (memory, guardrails, handoffs to other agents, structured outputs) is sugar around that loop.
The reason this matters is that the choice of “which OpenAI surface” you build on is mostly a choice about how much of that loop you want to manage yourself. The chat completions API gives you all of it. The Agents SDK manages the loop and exposes the primitives you customise. AgentKit hides the loop behind a visual canvas. The model is doing the same work in all three. The interface is what changes.
The 2026 model lineup, and which we pick when
OpenAI’s current production-relevant models, with the picks we default to:
gpt-4.1: our default for general-purpose agent work. Fast, broadly capable, good tool-calling accuracy. Most workflows we ship default to this.gpt-4o: still strong, slightly cheaper than 4.1 for some workloads. We keep it on standby for cost-sensitive endpoints.gpt-4o-mini: the cheap-and-cheerful option. We use it for high-volume classification and routing where the task is well-bounded.o3: the reasoning model. Slow and expensive, but for hard analytical tasks (code review, multi-step planning, anything that needs genuine working memory) it earns the cost.
The honest truth is that for most agent work, model choice matters less than tool design. We have spent more debugging time on bad tool descriptions than on bad model picks. That said, we will reach for Claude Sonnet 4.5 over GPT-4.1 for unstructured document extraction, and reach for o3 over either of them for reasoning-heavy tasks where latency does not matter.
The Agents SDK is now the default
If you are starting a new agent today, the Agents SDK is where you should start. It manages the run loop, gives you primitives for tools, handoffs between agents, guardrails on inputs and outputs, and a tracing dashboard that records every step. It is open source, runs anywhere you can run Python or TypeScript, and the same primitives back the AgentKit visual builder.
A minimum viable agent in the Agents SDK is short enough to fit on a screen:
from agents import Agent, Runner, function_tool
import httpx
@function_tool
def get_company_info(domain: str) -> dict:
"""Look up basic company info by domain. Returns name, industry, headcount."""
response = httpx.get(
f"https://api.example.com/companies?domain={domain}",
timeout=10,
)
return response.json()
researcher = Agent(
name="company_researcher",
model="gpt-4.1",
instructions=(
"You research companies given a domain. "
"Use get_company_info to fetch basic data, then summarise."
),
tools=[get_company_info],
)
result = Runner.run_sync(researcher, "Research osher.com.au")
print(result.final_output)
Twenty lines, including imports. Everything you would have written by hand in 2024 (the loop, the tool dispatch, the message threading) is gone. What you write is the parts that are specific to your problem: the tools, the instructions, and the model.
When to keep using raw chat completions
Not everything wants to be an agent. If your task is “send a transcript, get back a structured summary”, you do not need a loop. You need one chat completion call with a structured output schema and you are done. We use chat completions directly for classification, single-shot extraction, drafting, and any case where there are no tools and no decisions to make.
The mistake we see most often: dressing up a single prompt as an agent because the word is fashionable. If your “agent” has zero tools and runs once per request, it is a prompt. Call it a prompt. Skip the SDK. You will save complexity, latency, and a bit of money.
Tool design is where production agents are won and lost
The single biggest debugging session we have lost time on involved a procurement agent that was choosing the wrong tool roughly one call in five. The model was fine. The tools were fine. The descriptions were ambiguous, and the model was guessing.
What we learned: every tool description should include a one-line statement of purpose, the input shape with example values, and at least one sentence about when the tool should not be called. The “should not” sentence is the one most teams skip and it is the one that fixes most accuracy problems. Our procurement agent’s accuracy went from 79 percent to 94 percent on the eval set with no model change, just better descriptions.
Other patterns that pay back:
- Return structured data from tools. The model handles JSON better than it handles prose summaries of JSON.
- Validate tool inputs server-side before executing. The model will sometimes hallucinate field names. Catch it at your boundary.
- Cap your loop. We default to twelve steps. Anything that needs more usually has a tool design problem.
- Log every tool call with arguments and outputs. The Agents SDK’s built-in tracing is good. Use it.
Memory: how much, where, when
Most agents do not need persistent memory. They process one request, return a result, and forget. Persistent memory is for agents that hold a multi-turn conversation, accumulate context over time, or need to recognise a returning user.
When we do need it, the cheap and effective pattern is a Postgres table keyed by user or conversation ID, with a JSON column for any structured state and a separate table for raw message history. The Agents SDK’s session abstraction handles this neatly if you implement the storage interface. We have built this perhaps eight times now and the schema is the same every time.
For RAG over private documents, OpenAI’s hosted vector stores are convenient if your data fits the model. For larger or more heterogeneous corpora, we use Postgres with pgvector and our own embedding pipeline. The hosted version is faster to ship; the self-hosted version is cheaper at scale and more flexible when you have to debug retrieval quality.
Evals are not optional
Every agent we ship has an evaluation suite that runs before any prompt or tool change goes to production. The suite is twenty to fifty real example inputs with known good outputs, scored automatically. If a change drops accuracy on the eval set, it doesn’t ship.
We have rolled back exactly twice in three years because of a model upgrade that quietly degraded accuracy on a downstream task. Both times the eval suite caught it inside an hour. Without evals, the regressions would have shipped to production and we would have found out from a frustrated user a week later.
When we don’t reach for OpenAI
For unstructured document extraction (medical records, legal contracts, multi-page PDFs with mixed tables and prose), Claude Sonnet 4.5 has been better in every head-to-head we have run since late 2025. The gap is not huge but it is consistent. We default to Claude for that work and use OpenAI for everything else.
For workflows where the LLM is making one decision inside a mostly deterministic pipeline, we use n8n with an OpenAI node rather than the Agents SDK. Faster to build, easier for non-developers to maintain, and the LLM call is one node out of many. We have written more about that pattern in our piece on building an AI agent with n8n and OpenAI.
For agents that need to run inside a customer’s own VPC with no outbound API calls allowed, OpenAI is off the table entirely. Self-hosted models on vLLM or Ollama become the answer. The Llama 3 family is our usual starting point; our piece on running Llama 3 locally covers the hardware and tooling.
Realistic cost expectations
For a typical mid-volume agent (a few thousand runs per day, average five tool calls per run, gpt-4.1 as the underlying model), monthly OpenAI costs land somewhere between $200 and $1,500 USD. That is roughly $310 to $2,300 AUD at current rates. Costs scale linearly with run count and step count.
The biggest cost sink is agents that loop too long. Our twelve-step cap is not just for accuracy; it is also for spend protection. We have seen unbounded agents accidentally generate hundreds of dollars of usage in a single afternoon when a tool started returning malformed results that the model kept retrying.
For Australian customers worried about exchange rate volatility, the practical answer is to set a USD-denominated monthly budget cap in the OpenAI dashboard. We do this for every client production account, set conservatively above expected usage. Useful as a safety net.
Getting started without overbuilding
Concrete first steps:
- Pick one bounded task. “Draft a reply to support tickets that match this template” beats “an agent that handles support”.
- Build it as a single chat completion call first. If that works, you don’t need an agent.
- If you genuinely need tools, move to the Agents SDK. Start with one tool. Add more only when the agent has earned the trust.
- Build an eval set before the agent goes anywhere near production. Twenty examples is enough to start.
- Set a step limit and a daily spend cap. Both. Belt and braces.
If you want a hand picking the right first agent for your team, book a call and we will work through the candidates with you.
Frequently Asked Questions
Should I use the Agents SDK or AgentKit?
For prototypes, agents owned by non-developers, or anything you want to demo in an hour, AgentKit’s visual builder. For agents your engineering team will own and version-control, the Agents SDK in code. They share the same primitives so the choice is really about who is editing the agent and how often.
Which OpenAI model should I default to for an agent?
gpt-4.1 for general-purpose work. gpt-4o-mini for high-volume classification or routing where the task is well-bounded. o3 for reasoning-heavy work where latency does not matter. Avoid gpt-3.5-turbo in any new build; it is materially behind and the cost savings are no longer worth the accuracy hit.
What is the difference between tools and function calls?
Same primitive, different naming. The OpenAI API used to call them function calls. The Agents SDK calls them tools. They are functions you expose to the model that the model can choose to call. Use the term tools and you will be aligned with current docs.
What does it cost to run a production agent on OpenAI?
Highly variable. Mid-volume agents typically cost $200 to $1,500 USD per month (roughly $310 to $2,300 AUD). Cost scales with run count, average step count per run, and whether you are using hosted tools like web search. Always set a daily spend cap before going to production.
Where can I find a working tutorial?
The OpenAI Agents SDK docs include a quickstart that takes about twenty minutes end-to-end. For a longer worked example, see our walkthrough of building an AI agent with Claude. The structure transfers to the Agents SDK with minimal changes.
What goes in the agent’s instructions and what goes in the system message?
In the Agents SDK, the agent’s instructions field becomes the system message at runtime. There is no separate slot. Put the agent’s role, the rules it should follow, and the tools it has available. Keep it under a few hundred tokens. Long instructions degrade tool selection accuracy more than people expect.
When should I use multiple agents that hand off to each other?
When the task has clearly separable phases that benefit from different instructions or different tool sets. A triage-then-resolve workflow is a classic case: a small triage agent decides which specialist agent should handle the request, hands off, and the specialist completes. For tasks that flow together naturally, a single agent with a richer toolset is simpler and usually faster.
How do we handle Australian data residency for OpenAI agents?
OpenAI offers data residency in selected regions but Sydney is not one of them at the time of writing. For workloads that genuinely need Australian residency (My Health Records data, certain APRA-regulated workloads), use AWS Bedrock with the Anthropic models in ap-southeast-2 instead, or self-host a Llama-family model on Australian infrastructure. We have built both patterns and would be happy to talk through which one fits.
Where to from here
Build the smallest agent you can ship. Run it for two weeks. Look at the traces. Notice what surprises you. That is the loop that produces good production agents.
If you would like a hand picking the agent worth building first, or working out whether OpenAI is even the right provider for your use case, get in touch. We have built enough of these to know which ones earn their place.
Last updated on July 1, 2026
Continue Reading
View all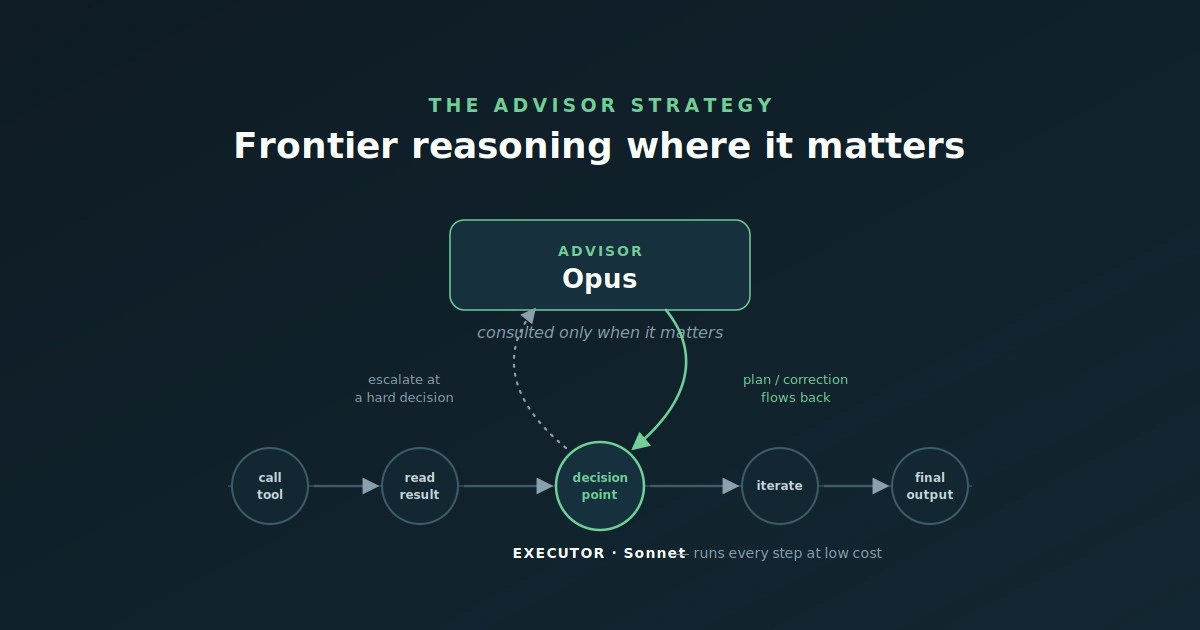
The Advisor Strategy: Frontier-Model Reasoning at a Fraction of the Cost
How Anthropic’s advisor strategy pairs a cheap Claude executor with an Opus advisor to lift AI agent quality while cutting cost, and how Osher Digital applies it.
Jul 1, 2026

Your 2026 Guide to AI Receptionist Australia
The usual trigger for looking at an AI receptionist isn’t curiosity. It’s frustration. Calls are going unanswered. Reception staff are stretched. After-hours enquiries sit in voicemail until morning, and by then the caller may have moved on. In a medium or large organisation, that problem rarely stays at the front desk. It spills into sales, […]
May 25, 2026

AI Assistants Are Collaborating With Each Other Now
AI agents are learning to work together, consume APIs, and execute workflows autonomously. Here’s why infrastructure, not prompts, is the real unlock.
Feb 8, 2026
Sick of reading about automation?
Book a free 15-minute intro call. We’ll talk through what you’re trying to automate and whether we’re a good fit.