The Advisor Strategy: Frontier-Model Reasoning at a Fraction of the Cost
How Anthropic’s advisor strategy pairs a cheap Claude executor with an Opus advisor to lift AI agent quality while cutting cost, and how Osher Digital applies it.
By Matthew Clarkson · July 1, 2026
Most businesses running AI agents at any real volume hit the same wall. The models that reason well enough to handle genuinely hard decisions are too expensive to run on every step. The cheaper models keep costs sane but occasionally make a call that costs you real money. For a long time, the choice was binary: pay for intelligence on everything, or accept that a fast, cheap agent will sometimes get the important moments wrong.
Anthropic’s advisor strategy removes that trade-off. It lets a cheap, fast model run the whole job and pull in a frontier-grade model only at the handful of moments where judgment actually matters. At Osher Digital we build automation and AI agents for Australian businesses where the numbers have to stack up, so a pattern that lifts quality while cutting cost is worth a close look. This article explains how it works, where it earns its keep, and how we are applying it in production.
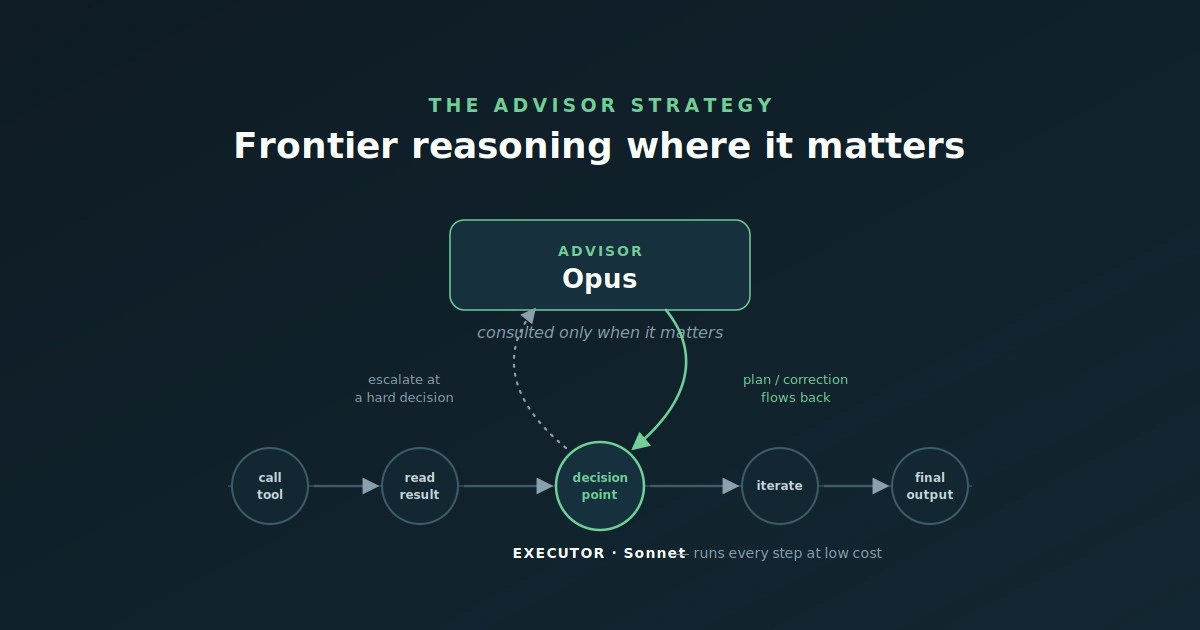
What the advisor strategy actually is
The advisor strategy pairs two models on a single task. A lower-cost model — Claude Sonnet or Haiku — runs as the executor. It does everything visible in the workflow: calling tools, reading results, browsing, iterating, and writing the final output. A more capable model — Claude Opus — sits behind it as the advisor. When the executor hits a decision it cannot reasonably resolve on its own, it consults the advisor, which reads the shared context and returns a plan, a course correction, or a stop signal. The executor then resumes.
The advisor never calls tools and never produces output the user sees. Its only job is to give the executor guidance at the right moment. Anthropic released this as a formal API primitive on 9 April 2026: a server-side tool, advisor_20260301, that handles the model handoff inside a single API request with no orchestration layer to build or maintain.
This inverts the usual multi-model setup. The common pattern is a large “orchestrator” model that decomposes a task and delegates chunks to smaller workers. The advisor strategy does the opposite. The smaller, cheaper model drives the whole run and escalates only when it needs to. There is no task decomposition, no worker pool, no orchestration logic. Frontier-level reasoning is applied only where the executor asks for it, and everything else runs at executor-level cost.
The analogy that fits best: a capable junior analyst doing the legwork — running the queries, gathering the data, drafting the outputs — with a senior strategist on call for the two or three moments where experience changes the outcome. You are not paying the strategist’s rate for every spreadsheet cell.
Why this works: most steps do not need a frontier model
The insight underneath the strategy is simple. In a typical agent loop, most turns are mechanical. Parsing a tool result, deciding which tool to call next, formatting an output, handling routine branching — a cheaper model handles all of that competently.
The turns that genuinely benefit from a frontier model are a small fraction of the total. There is usually an ambiguous problem to decompose at the start of a complex task. There is the occasional judgment call about which of several approaches is more likely to succeed. And there are the decision points where the cost of getting it wrong is high. Reserve the advisor for those, and you capture most of the quality benefit for a fraction of the spend.
The cost shape is the whole point. The advisor produces a short response — Anthropic estimates roughly 400 to 700 tokens per consultation — and that is the only place you pay frontier rates. Everything the executor generates, which is the bulk of the tokens, stays at the executor’s lower rate.
The numbers Anthropic published
Anthropic released benchmark results alongside the launch, and they show a consistent pattern.
On SWE-bench Multilingual, which measures the ability to find and fix software bugs across nine programming languages, Sonnet with an Opus advisor scored 2.7 percentage points higher than Sonnet alone, while reducing cost per agentic task by 11.9%. That is the unusual case where you gain accuracy and save money at the same time.
The Haiku result is more dramatic. On BrowseComp, a benchmark that tests multi-step web research, Haiku with an Opus advisor jumped from 19.7% to 41.2% — more than double its solo score. It still trails Sonnet-solo on raw accuracy by around 29%, but it costs roughly 85% less per task, which makes it a strong option for high-volume pipelines that need a balance of intelligence and cost.
The clear takeaway: the advisor strategy delivers its biggest gains when the baseline executor is weakest and the task involves real planning. The cheaper the executor and the harder the reasoning, the more the advisor earns its place.
How it works under the bonnet
The mechanics are deliberately minimal, which is part of why it is worth adopting.
You add one beta header and one tool definition to a standard Messages API request. The executor is the model in the top-level model field. You declare advisor_20260301 in the tools array and name the advisor model. From there, the executor decides when to call it, exactly like any other tool.
python
import anthropic
client = anthropic.Anthropic()
response = client.beta.messages.create(
model="claude-sonnet-5-0", # executor
max_tokens=4096,
betas=["advisor-tool-2026-03-01"],
tools=[
{
"type": "advisor_20260301",
"name": "advisor",
"model": "claude-opus-4-9", # advisor
"max_uses": 3,
}
],
messages=[
{
"role": "user",
"content": "Build a concurrent worker pool in Go with graceful shutdown.",
}
],
)
When the executor calls the advisor, the API routes the shared context to the advisor model, drops the advisor’s internal thinking, and returns just the guidance as a tool result. The executor keeps generating, now better informed, with no context-switching overhead because both models share the same conversation state. One request, one coherent agent run.
A few controls matter in production. The max_uses parameter caps how many times the advisor can be consulted per task, which keeps cost predictable. Advisor tokens are reported separately in the usage block, so you can watch exactly what you are spending on the advisor versus the executor. The advisor must be at least as capable as the executor. And the tool sits alongside other tools — web search, code execution, custom tools — in the same loop, so the executor can browse, run code, call your systems, and consult the advisor all in one run.
The single biggest implementation decision is when the executor should consult the advisor. Get it wrong in either direction and you lose the benefit. Consult too often and the cost advantage evaporates and latency rises. Consult too rarely and the quality lift never materialises. The most reliable approach is to define escalation around specific decision types — plan the task, evaluate whether an output meets standard, recover from a failed approach — rather than leaving the executor to judge on every single turn.
Where this fits the work we do at Osher Digital
We build business process automation and AI agents for Australian organisations, and we are platform-agnostic by design — n8n, Make, RPA bots, and both OpenAI and Anthropic Claude, chosen to fit the business rather than the other way round. The advisor strategy fits our world well because our agents run in exactly the conditions it was built for: long-horizon tasks where most turns are routine but a few decisions carry weight, and where the automation has to pay for itself. Here are tactical examples of how it applies.
1. Document classification and intake, at scale
We have built systems that classify and file incoming documents automatically – medical records for a Melbourne practice, job requests for a recruitment agency pulled straight out of email. The bulk of that work is repetitive: read the document, extract fields, name it consistently, route it to the right place. A cheap executor handles the routine documents fine.
The advisor earns its place on the awkward ones – an ambiguous document type, a record that could reasonably file two ways, a malformed input the executor cannot confidently parse. Instead of running every document through a frontier model or accepting misfiles on the hard 5%, the executor processes the clear majority cheaply and escalates only the genuinely ambiguous cases. You get consistent, accurate filing across the full range of inputs without paying frontier rates on the easy 95%.
2. Email-to-CRM pipelines that handle any format
One of our recruitment clients receives job requests by email in every format imaginable, and we extract the details and push them into their CRM with a link back to the source. A neat, well-structured email is trivial. The value of an advisor shows up when a message is genuinely messy with details buried in a forwarded thread, conflicting information, a format the executor has not seen before.
Wire an advisor consultation into the “I am not confident how to structure this” branch, and the executor resolves those edge cases with frontier-grade judgment while the standard-format majority flows through at executor cost. Fewer bad records reaching the CRM, no blanket cost increase.
3. AI agents that recover from their own errors
The place the advisor strategy is most valuable is error recovery in long-running agents. When an agent building or maintaining a workflow hits an unexpected failure — an API returns something malformed, a step fails, a data pipeline behaves in a way the executor did not anticipate — that is precisely the decision point where a frontier model’s judgment prevents a bad recovery choice from cascading. Reserve the advisor for “this failed and I need to decide how to recover” and the executor handles the happy path cheaply while the hard recoveries get proper reasoning.
4. Coding and system-integration agents
Our team builds and maintains integrations across 800-plus tools, and increasingly the agents themselves write and adjust code. The benchmark data maps directly onto this: a Sonnet executor with an Opus advisor beat Sonnet alone on real multi-language bug-fixing while costing less. In practice that means an executor writing the routine integration code and consulting the advisor at the moments that decide whether a patch actually works — the architecture call at the start, the tricky bit of logic in the middle. Fewer broken patches, lower cost per task.
5. Multi-step research and data-gathering agents
For agents that gather and synthesise information across many sources — the kind of research task where a single wrong turn early sends the whole run down a dead end — the BrowseComp numbers are the headline. A cheap executor becomes genuinely competent on multi-step research when it can consult a frontier model at the branch points. For high-volume research pipelines, where thousands of runs a day make the cost delta compound, a Haiku executor with an advisor can be the difference between “too expensive to run” and “runs profitably”.
The strategic read
The advisor strategy is no longer “which model do we use for this workflow” but “which model runs by default, and where do we buy in frontier reasoning”. For any organisation watching its token bill while still needing high-quality decisions in the critical path, that is exactly the lever worth having: smart when it needs to be, cheap the rest of the time.
That maps precisely onto how we think about automation at Osher Digital. We only build the automations that pay for themselves, and we tell clients upfront when the numbers do not stack up. A pattern that lifts the quality of an AI agent’s key decisions while lowering its running cost is not a marginal tuning trick. It is a genuine improvement to the economics of putting agents into production.
Where to start
If you are already running Claude-based agents, the lowest-risk first step is the evaluation recipe Anthropic recommends: run your existing eval suite three ways — executor solo, executor with an advisor, and advisor solo — and read the cost-quality trade-off in your own environment rather than on a benchmark. That tells you where the advisor actually earns its place in your workload.
If you are weighing up where AI agents fit in your business and want the economics to be honest from the start, that is the conversation we have every day. Book a free process audit and we will give you a straight view of what is worth automating and what is not.
Last updated on July 1, 2026
Continue Reading
View all
AI Driven Decision Making for Australian Enterprises
Unlock growth with AI driven decision making. Our guide for Australian enterprises covers strategy, governance, & implementation for smarter, faster decisions.
Jul 17, 2026

What Is Semantic? A Comprehensive Guide for 2026
What is semantic and why does it matter for your business? Understand semantic tech, from AI to search, for enterprise automation.
Jul 17, 2026

Workflow Orchestration: A Business Leader's Guide
Learn workflow orchestration with simple analogies. A guide for leaders on its architecture, ROI, implementation, & how it differs from automation.
Jul 17, 2026
Sick of reading about automation?
Book a free 15-minute intro call. We’ll talk through what you’re trying to automate and whether we’re a good fit.